哥几个,走过路过别错过,今天的 AI 圈可以说是格外热闹了。
真正 “Open” 的 DeepSeek ,打出开源周的第二发炮弹,短短几个小时就已经在 GitHub 上,收获了 3k 多星。
“ 开源老兵 ” 阿里通义千问也没闲着,推出了 QwQ-Max-Preview 深度思考模型,展示思维链,还支持联网搜索。
还有凌晨两点多,大伙儿可能还在做梦的时候,大洋彼岸的 Anthropic 也给模型升级换代了。号称他们迄今为止最聪明的 Claude 3.7 Sonnet ,还是个推理模型和传统模型的 “ 混血 ” 。
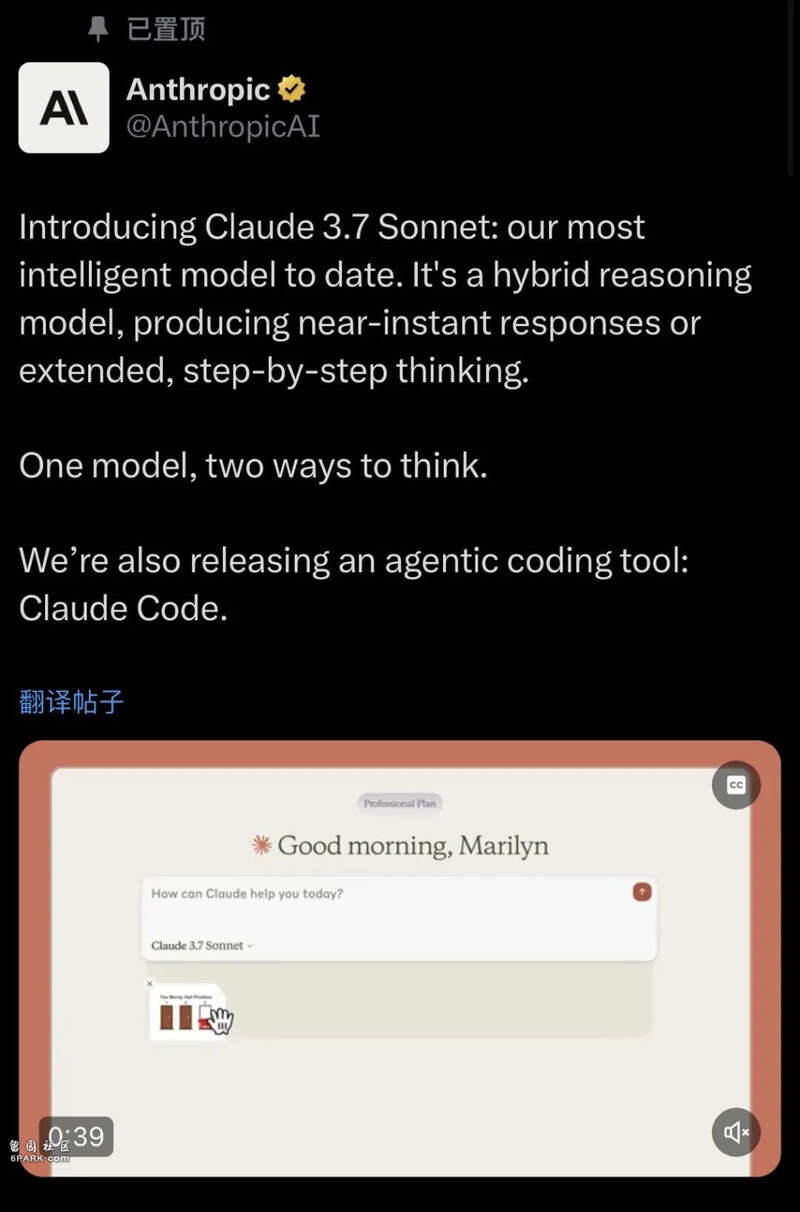
我估计今天那些专门做模型测评的博主,都快要忙不过来了吧。。。
再加上 Grok 3 、 DeepSeek R1 、 o3 mini ,世超猜到了今年推理模型必有一战,但没想到,来得这么快。
光这么说大伙儿估计也没感受,今天咱们就挨个来看看, AI 圈子到底是怎么个热闹法。
先把视线,放在新一代 “ 开源战神 ” DeepSeek 身上。
用 R1 教育了一遍市场之后, DeepSeek 这两天,干脆开源了个彻底, 5 天时间,每天发一个代码库。
第一天,整了个 FlashMLA ,这玩意儿专门针对英伟达的 Hoppers GPU ( 比如 H100 、 H800 ),进行了效率优化,通俗点说就是榨干 GPU 的最后一滴性能。

今天开源的,则是 DeepEP 通信库。
根据官方的介绍,这是一个专门为专家混合( MoE )和专家并行( EP )设计的通信库。太复杂的咱也不去深究,大白话就是通信库可以让 “ 专家们 ” 的交流更快速、高效。
盲猜一波,国内那些个手里有 Hoppers GPU ,还是研究 MOE 模型的 AI 公司,可能已经冲了。
不知道明天 DeepSeek 又会开源哪个代码库,但光凭他们这敞亮、真诚的态度,圈粉就是分分钟的事儿,在 DeepSeek 的评论区底下,世超已经看到不只一位老哥,对着 OpenAI 贴脸开大了。
不过说到这,可能会有差友疑惑,网上整天嚷嚷着开源,这跟咱到底有啥关系?
这么说吧, DeepSeek R1 开源以后,大大小小的私企、国企都吻了上来,还有高校甚至政府机关,不是已经接入 DeepSeek ,就是在接入的路上。
经过大规模的模型部署后,下一步就是生态的构建、产业的融合,就像当年的 “ 互联网 +” , AI 同样也可以成为基础设施,融入到咱们生活的方方面面。
很难说,闭源模型在构建生态这一步,能不能在短时间内达到像 DeepSeek 这样的效果。
所以这一切,我们可能都得感谢开源。

再来看阿里通义千问的 QwQ-Max-Preview ,是个推理模型。阿里也算是国内第一个,推出推理模型的头部大厂。
根据官方的说法,这是一个基于 Qwen2.5-Max 的推理模型,有很强的数学理解、编码能力,但目前还只是预览版。
世超在第一时间简单试了试, QwQ 也有思维链的展示。(不得不说,QwQ这名字有点可爱。。)

问它一道数学竞赛真题,最后的答案倒是对了,就是思考时间稍微久了些,我粗略估计思考了得有两分钟出头。
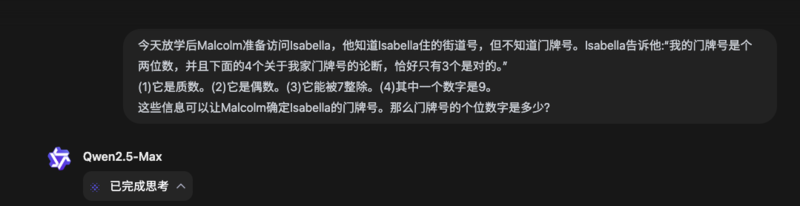
这道题问 DeepSeek R1 ,它的思考过程跟 QwQ 很相似,也是分析了多种可能性,但 R1 胜在推理的速度稍微快一些( 112 秒 )。
而同样的题目,我又问了今天的另外一位主角 Claude 3.7 Sonnet 。
只能说,又快又准。

但值得注意的是, Claude 3.7 Sonnet 是个混合模型,一个模型有标准和扩展两种模式。
如果你想看到大模型的推理步骤、思考过程,那就得选扩展模式。
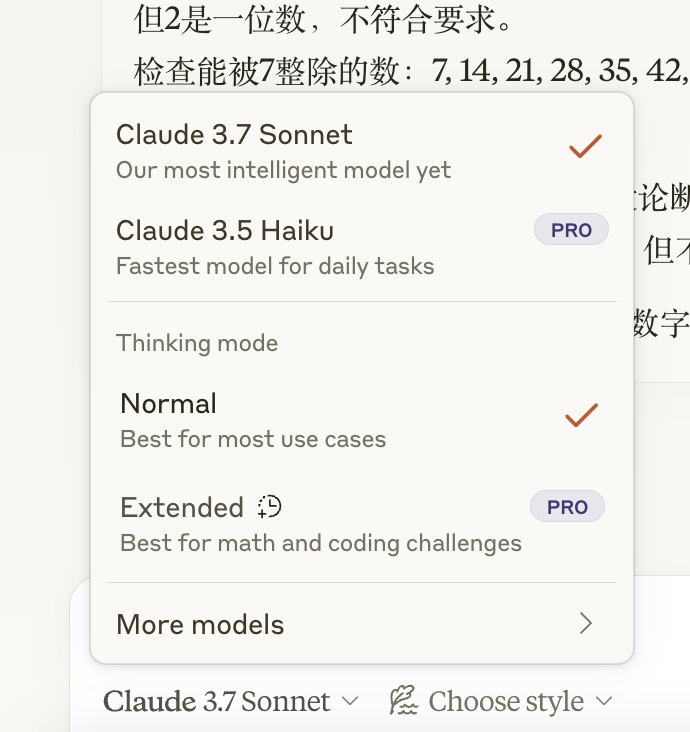
如大伙儿所见,体验 Claude 3.7 Sonnet 的推理能力,是另外的价格。
世超还找了几个外网的实测案例,发现 Claude 的代码能力依然强得可怕。
同一组提示词喂给 Claude 3.7 Sonnet 和 Grok 3 ,这是 Claude 3.7 Sonnet 的结果。


