你有没有想过,当你在网上进行简单的验证码操作时,其实你已经无意间成为了一名“标注民工”?
昨天晚上,我在登录QQ邮箱和LOL官网的时候。
发现腾讯的验证码变了。
不再是之前的验证码了,而是变成了一段Prompt加六张AI生成的图。
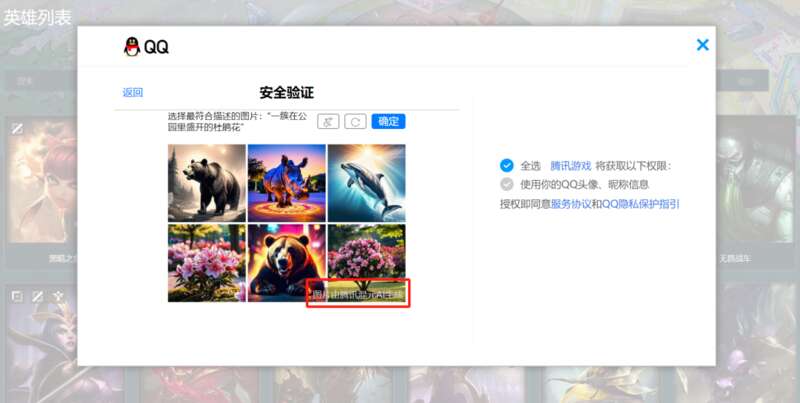
右下角赫然写着:
图片由混元AI生成。
腾讯,终于把用验证码做标注的手,伸向了他那12亿的用户。
拿验证码当标注系统,让用户免费标注,其实在远古时代,就已经不是什么新鲜事了,但是用生成式AI来跟验证码做结合,这确实还是我,所看的头一回。
先说说验证码这个东西。
这玩意从最开始发明起,其实只有一个目的,就是为了区分机器和人。
简称“CAPTCHA”,全称就贼长了,“Completely Automated Public Turing Test to Tell Computers and Humans Apart”
翻译过来是,“全自动区分计算机和人类的图灵测试”。
你看看,图灵测试。
刚开始,有个斯坦福公益验证码系统,reCAPTCHA。
它最成名的项目,就是用验证码来数字化海量的书籍和旧报纸。那时候的Ocr真的不咋地,而且很多年前的书和报纸那糊的真的差强人意。
当时,reCAPTCHA系统会向用户在验证码上,展示两组扭曲的单词,其中前面的一组是计算机已经识别的,另一个是计算机难以识别的。
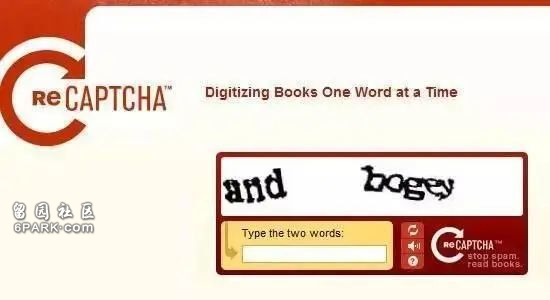
如果用户正确输入前半部分,那么 reCAPTCHA就会假设用户输入的后半部分也是正确的,然后把录入结果返回至reCAPTCHA的项目主机。
结果返回主机后,主机还会把这个结果再派发给多个用户进行交叉验证,以确保没有不小心或故意输错单词的情况。
他们用这个系统,在十几年里,数字化了几千万的书籍和报纸。
本来一切都挺美好的,然后,Google下场了,他们把reCAPTCHA给收了。
没过多久,就让用户开始识别,google街景中,那些难以识别的门牌号了。。。

这其实,就是明晃晃的让你当标注民工,无偿来给google标注训模型了。
google那时候几亿用户,每天验证码会被调用上千万次。
这大概就好像,让几百万个人每人为给你干5秒钟活儿,然后一分钱都不给一样,你说这是不是已经,把白嫖玩到极致了。
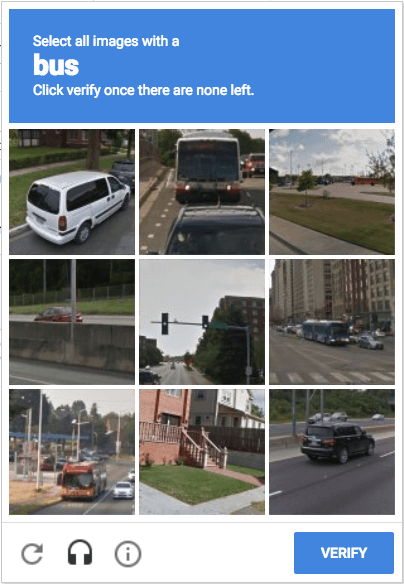
直到后面,离谱的东西越来越多,你要标注的东西,也越来越多。
比如这些奇奇怪怪非人视角让你选一个bus的照片。
当然最离谱最好玩的,得数15年的12306,当时开脚本抢票的太多,12306的流量压力实在太大,被逼的开启了神迹级的验证码,据说人类首次正确率仅为8%,得错3次以上的人占比有65%。
这种逆天验证码的题目是这样的。

刘慈欣我不敢打包票,但是范伟我是全认出来了。。
时间走走停停,一眨眼,来到了2024年。
为了自己家的混元大模型,腾讯也把手,伸向了验证码。
让我们开始,来做AI绘图大模型的标注了。
这部分的标注,其实不是啥图片美学质量的标注,而是对于图片理解和映射的标注。
通俗地讲,就是语义理解。
现在做的,还是最基础最简单的分类,我们标起来,还是挺轻松的。毕竟里面都知道,左上角是鸭子,中间是老虎,左下角是蜜蜂,右下角是赛车。
而那两张白杨树林,其实,你选任意一个,或者选两个,都能过。
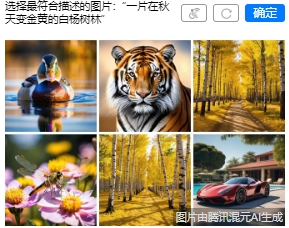
比如我这个图:一簇在悬挂花盆在生长的多肉。

其实你会看到有两张都跟多肉有关,而根据定语,一簇,更符合左上角第一张图,右上角那个其实不是一簇是一堆,但是我选了他,依然能过。
而你想把两个都选,你也都能过。
所以这个标注之心啊,一点都不藏着掖着。
但是确实这个做法很有用,比如还是这句Prompt,真正核心难点是一簇。
用这种方式,对整体的语义理解,确实有非常大的帮助。
而且现在明显还是初期,给的prompt和图,都非常的简单,标注的难度也不高,甚至一些大厂的标注模型直接机标可能都应付的过来。
但是如果下一次,是“一只在清朝宫殿里生长的杜鹃花”呢?
一只、清朝宫殿、杜鹃花。难度直接拉满。
甚至另外几个选项给你的也不是差异这么大的动物汽车啥的,给你的都是菊花、杜鹃花、喇叭花、玫瑰花,来吧你就选吧,加油啊标注民工。
要知道,标注真的很贵的,之前跟国内一家做AI绘图大模型的公司聊过,才知道他们标注分为机标和人标,而人标的成本,大概是数据量的十分之一。
也就是你拿出去3000万的数据,人工标一次,就得300万RMB干出去。
而腾讯12亿用户,每天验证码起码也是千万的量级,这标注费用,你可以算算这省了多少钱吧。
所以说,大厂在如今还在大数据的时代,优势是真的大。。。
不过这种标注,目前来看还是只能解决语义理解的标注,但是能把这个解决也已经很牛逼了,虽然美学一般,但是语义理解能达到极强,这就是妥妥的国内版Dalle3。
而Dalle3的短板大家肯定也清楚,实在太丑了。
而要标美学表现,难度其实就大很多,真的得找懂设计、懂美学的人来标注。
Midjourney当年其实就是吃了这波红利。
第一波获得用户,而且获得的还是一大波的有美学背景的专业用户,然后每次你生图的时候给你生成4张图拼一块的一张整图,你还必须选一张你觉得最好的进行提取或优化。

这就是一种强行的数据标注。
所以Midjourney在如今的美学表现上一骑绝尘,是因为他们在美学的标注上,做的太好了,而别的家想在这块赶上,基本不可能,因为最高质量的那波用户,基本已经全在Midjourney那了。
而腾讯未来想做这件事,其实在我看来,还真是有可能的。
因为你其实看Midjourney的路径,核心点就一个:海量的专业用户。
腾讯缺专业用户吗,怎么可能会缺,12亿用户捏在手上,用户画像做的那么齐全,我想把有设计师背景的用户挑出来,难吗?一点都不难。
我想给挑出来的这些设计师背景的用户推送美学标注的验证码,难吗?也不难。
所以啊,现在在我看来,腾讯的验证码标注,才刚刚向前迈了半步,后面的模型空间,还很大。
唯一问题就是,腾讯内部有点封闭,用户画像数据PCG做QQ的那边肯定有,但是混元跟PCG不是一个事业群,也不知道能不能拿得到。。。
能拿到的话,那就是王炸。
但是不管怎样。
你我都已经,身在其中了。
10年前,就已经是了。
Advertisements


