
香港中文大学(深圳)数据科学学院武执政副教授团队联合上海人工智能实验室 OpenMMLab 团队开源了综合音频生成项目 Amphion(安菲翁)。该系统旨在打造一个集语音合成转换、歌声合成转换、音效音乐生成等多功能为一体的开源平台。截至目前,Amphion 已经多次进入 GitHub Trending Repositories 榜单。
2022 年被称为 AIGC 元年,ChatGPT、Stable Diffusion、MidJourney 为代表的文字、图像应用带火了 AI 领域。2023 年,AI 孙燕姿、AI 郭德纲、音效生成、音乐生成也在社交媒体上火了一把。
今天,我们还能听到泰勒 · 斯威夫特唱周杰伦的稻香。
这看似简单,但实际上背后的技术十分复杂,也正是由于音频领域的领域知识壁垒,工程师们上手并不容易。
近日,香港中文大学(深圳)数据科学学院武执政副教授团队联合上海人工智能实验室 OpenMMLab 团队开源了综合音频生成项目 Amphion(安菲翁)。该系统旨在打造一个面向科研群体及刚进入或想要进入该领域的工程师的,集语音合成及转换、歌声合成及转换、音效及音乐生成等多功能为一体的开源平台。目前,该研究已经在海外社交平台上引发了极大的关注。

项目地址: https://github.com/open-mmlab/Amphion
论文地址:https://arxiv.org/abs/2312.09911
OpenMMLab 在 AI 领域无人不知,是目前最具国际影响力的计算机视觉开源算法体系,在 GitHub 上获得超过 9 万星标,用户遍及全球 140 个国家和地区。联合实验室兄弟团队推出了性能领先的千亿级参数大语言模型 “书生・浦语”(InternLM),并建设了首个面向大模型研发与应用的全链条开源体系。该团队的研究成果还包括社区内规模最大、覆盖领域最完整的大模型评测平台 OpenCompass,推理性能领先的大模型推理框架 LMDeploy 等。
这是 OpenMMLab 第一次涉足音频与语音领域,相信这次开源会给多模态生成带来了更多的想象空间。在没有公开宣传之前,Amphion 已经数次进入 GitHub Trending Repositories 榜单。可以说,Amphion 一出生就自带光环。
Amphion
Amphion 是一个综合的音频生成平台。该项目涵盖多种经典的音频生成任务,如语音合成、语音转换、歌声合成、歌声转换、音效生成、音乐生成、语音增强,以及多元的 AIGC 音频任务,诸如多模态控制的音效生成和音乐生成。Amphion 独有的可视化功能可以帮助初级研究人员和工程师更好地理解相关模型,从而协助初级研究人员和工程师在音频、音乐和语音生成等方面实现可持续的研究与开发。

Amphion 技术报告详细对比了 Amphion 的一些任务和算法与 GitHub 上较受欢迎的开源系统在性能上的异同。总体来说,Amphion 用一个系统达到甚至超过了 GitHub 上相关任务多个热门系统。
SVC:歌声转换
对很多人来说,“歌声转换” 这个词可能比较陌生,但是不少人都应该听说过今年爆火的 “AI 孙燕姿”。“AI 孙燕姿” 背后的技术正是歌声转换。
通俗来说,歌声转换技术就是通过 AI 技术,把一个人唱歌的声音音色转变得听起来像另外一个人的技术。这一过程通常牵涉到信号处理、机器学习、深度学习等算法。Amphion 系统集成了经典的特征提取模型。除了集成了经典的扩散模型、VITS 模型外,还集成了来自大名鼎鼎的 OpenAI 的 Whisper 模型。为了得到好的音质,Amphion 集成了 BigVGAN、HiFi-GAN、DiffWave 等主流声码器。同时,Amphion 的声码器还集成了港中大(深圳)的最新成果。
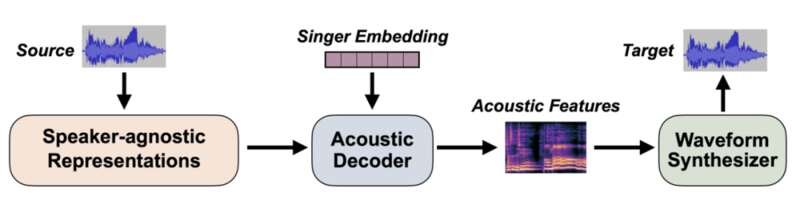
Amphion 的技术报告里的主观评测显示,Amphion 在自然度和相似度上均超过了之前流行的 So-VITS-SVC 系统。目前,Amphion 的特征设计已被 So-VITS-SVC 5.0 系统借鉴。
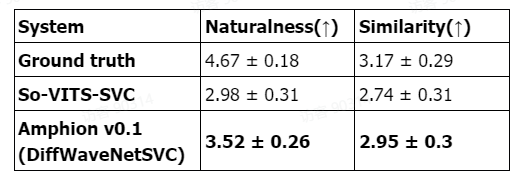
TTS:语音生成
语音生成即文语生成,指的是将文字输入转成相应的语音输出的技术。当前,该模块主要采用了深度学习技术,将文本转换成自然流畅的高拟真度的语音。该技术在有声电子书、视频配音等方面有广泛的应用。Amphion 系统实现了经典的 FastSpeech2 模型、VITS 模型等,以及最新流行的 zero-shot 语音合成技术,即 Vall-E,NaturalSpeech2。
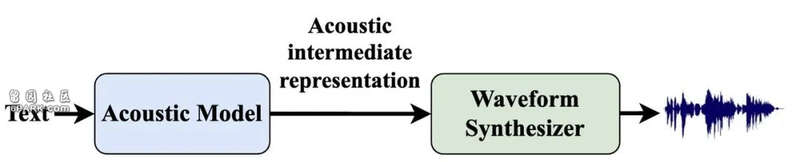
Amphion 的技术报告显示,在客观指标和主观指标上,Amphion 均达到乃至超越了当前最受关注的开源系统的水平。
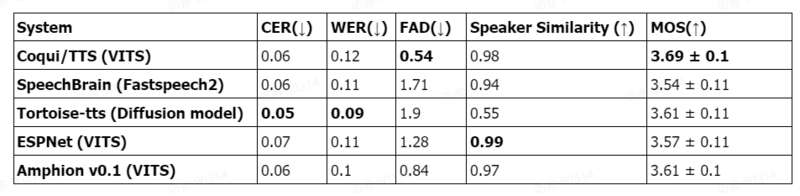
TTA:音频生成
文本驱动的生成模型在图像和视频领域均已取得显著成果。在图像领域,Stable Diffusion 和 MidJourney 已经可以生成高质量的图像;而在音频领域,文本到音频的生成模型必将对许多与创作相关的行业必将产生积极深远的影响。例如,游戏开发者或电影配音人员可以利用这项技术,根据特定的需求生成音效,而不必在庞大的音频效果数据库中进行搜索及编辑,从而提高生产效率。
Amphion 集成了当下最主流的文本驱动的音频生成模型架构,即基于 VAE Encoder、Decoder 和 Latent Diffusion 的文本驱动的音频生成算法。在该架构下,Latent Diffusion 扩散模型以 T5 编码后的文本为输入,根据文本的指引生成对应的音频效果。
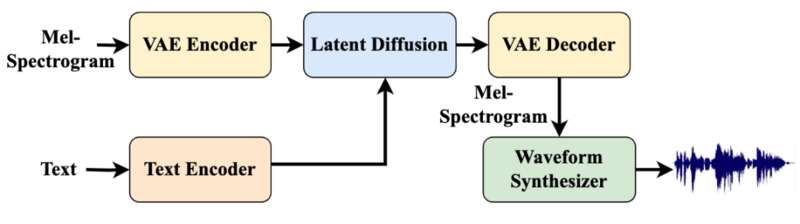
Amphion 的技术报告的客观指标显示,Amphion 在 TTA 任务上达到了领先的技术水平。
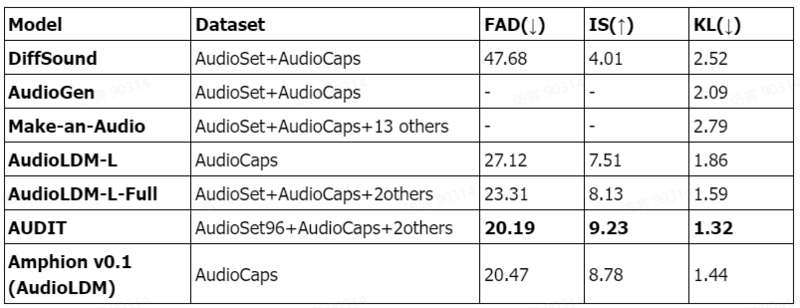
Vocoder:声码器
声码器(Vocoder)是音频、语音生成最重要的一个模块,也是确保声音合成质量的关键。Amphion 集成了 BigVGAN、HiFi-GAN、DiffWave 等主流声码器,也集成了港中大(深圳)最新发表的成果。
Amphion 的技术报告表明,Amphion 中的 HiFi-GAN 声码器在客观指标上均超过当前热门的开源工具。
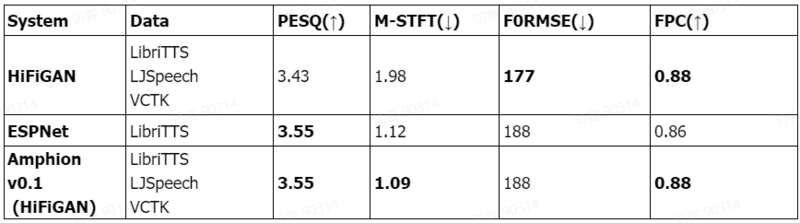
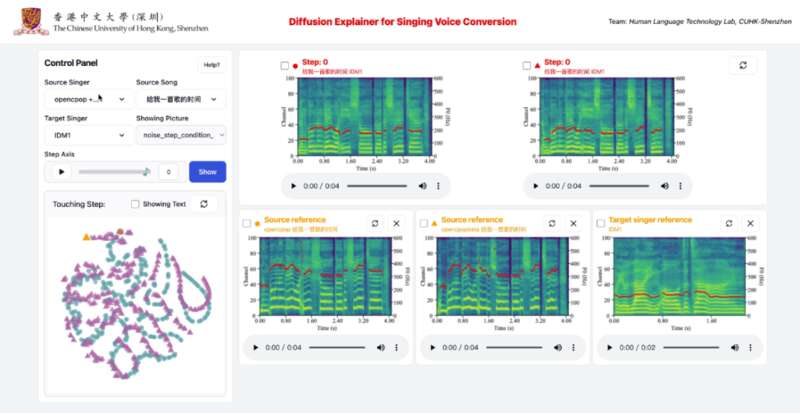
可视化
与传统的语音、音频开源工具不同,Amphion 提供了可视化功能。Amphion 团队希望可视化功能能让初学者更好地理解模型的原理和细节。目前,Amphion 团队提供了扩散模型的可视化截图。该功能通过扩散模型在歌声转换上的可视化,形象地呈现出一位歌手模仿另外一位歌手的渐变过程。
Amphion 团队
负责人:武执政博士
武执政博士现任香港中文大学(深圳)副教授。他曾入选国家级青年人才,连续多次入选斯坦福大学 “全球前 2%顶尖科学家”、爱思唯尔 “中国高被引学者” 榜单。他于 2015 年获得南洋理工大学博士学位,并先后在 Meta(原 Facebook)、京东、苹果、爱丁堡大学、微软亚洲研究院等多个机构从事学术研究和技术领导工作。武执政博士带领开发了语音合成开源系统 Merlin,发起并组织了第一届声纹识别欺骗检测国际评测、第一届语音转换国际评测,并组织了 2019 年语音合成国际评测(Blizzard Challenge 2019),曾获得 INTERSPEECH 2016 最佳学生论文奖、2012 年亚太信号与信息处理协会年度峰会最佳论文奖。他现在是 IEEE 语音与语言处理技术委员会委员,语音领域权威期刊 IEEE/ACM Transactions on Audio, Speech and Language Processing 的 Associate Editor,IEEE Spoken Language Technology Workshop 2024 的大会主席,曾受邀在 ICASSP 2022、ISCA SPSC Workshop、IJCAI 2023 DADA Workshop 等权威学术会议做特邀报告。
核心成员
Amphion 团队核心都是港中大(深圳)学生,他们的背景都相当亮眼,是妥妥的 “别人家的团队”。
共一张雪遥刚刚博二,他的文章却已经被谷歌学术引用数百次,且在 2023 年入选了全国仅 55 人的腾讯犀牛鸟精英人才计划;共一王远程带一作顶会 NeurIPS 直博入学港中大(深圳);共一薛浏蒙博士有微软、腾讯、京东等多家大厂的实习经历。
值得一提的是,Amphion 核心成员中还有两位港中大(深圳)大二学生。共一顾毅骋包揽了 Amphion 中声码器(vocoder)的所有代码,他大一入学三周即进组科研,大二第一学期即手握语音领域顶级会议文章;大二学生王超人也是人如其名,一个人包揽 Amphion 可视化部分的所有代码,而且他的个人开源系统在 GitHub 上已收获数千颗星。
Amphion 名字背后的含义
"Amphion" 取名自古希腊神话中传奇音乐家 Amphion。传说中,Amphion 以弹奏竖琴而著称,并运用他的音乐才能建造了底比斯城墙。据说他的琴声能感动树木和岩石。Amphion 团队希望借用安菲翁的音乐天赋和传奇,畅想项目助力科研和开发的美好愿景,擘画声音科技逐步迈向可持续发展的美好蓝图。

Amphion 在线 Demo 体验链接:
Text to Speech
HuggingFace Demo: https://huggingface.co/spaces/amphion/Text-to-Speech
OpenXLab应用: https://openxlab.org.cn/apps/detail/Amphion/Text-to-Speech
Singing Voice Conversion
HuggingFace Space: https://huggingface.co/spaces/amphion/singing_voice_conversion
OpenXLab应用: https://openxlab.org.cn/apps/detail/Amphion/singing_voice_conversion
Text to Audio
HuggingFace Demo: https://huggingface.co/spaces/amphion/Text-to-Audio
OpenXLab应用: https://openxlab.org.cn/apps/detail/Amphion/Text-to-Audio


