据外媒报道,在生成式 AI 竞争中处于落后的字节跳动想要“抄近道”,该公司一直在秘密使用 OpenAI 的技术开发自家大语言模型,这违反了 OpenAI 的服务条款。目前,字节跳动的账户已被 OpenAI 暂停。
据凤凰网科技报道,外媒称,在 AI 领域,字节跳动的这一做法通常被视为一种“失礼”行为,也直接违反了 OpenAI 的服务条款。
OpenAI 的服务条款规定,该公司所输出的模型不能被用于“开发任何与我们的产品和服务竞争的 AI 模型”。字节跳动通过微软购买了 OpenAI 的访问权限,但是微软也制定了与 OpenAI 同样的政策。
外媒获得的字节跳动内部文件证实,字节跳动在几乎每个开发阶段都依赖 OpenAI 的应用程序接口(API)来开发其代号为“种子计划”(Project Seed)的基础大语言模型,包括训练和评估模型。
参与“种子计划”的员工都深知这一行为的不良影响。根据字节跳动员工在内部通讯平台飞书海外版 Lark 的聊天记录,他们讨论了如何通过“数据脱敏”来粉饰证据。
外媒称,字节跳动员工大量使用 OpenAI 的技术,以至于“种子计划”的员工经常达到 OpenAI API 的最大访问上限。
内部文件显示,字节跳动更多的是在“种子计划”的早期阶段使用 OpenAI 的技术。几个月前,该公司命令该团队在“模型开发的任何阶段”停止使用 GPT 生成的文本。大约在这个时候,该公司获得了批准发布了自家 AI 大模型“豆包”,从而让“种子计划”上线。
但是,字节跳动继续以违反 OpenAI 和微软服务条款的方式使用 API,包括评估豆包背后模型的性能。一位对字节跳动内部情况有第一手了解的人指出,“他们说他们想确保一切都是合法的,但他们实际上只是不想被抓住把柄”。
字节跳动发言人约迪・赛斯(Jodi Seth)对此回应称,GPT 生成的数据在“种子计划”的早期开发中用于注解模型,并且在2023年年中左右的时候已从字节跳动的训练数据中删除。
“字节跳动获得了微软的许可能够使用 GPT API。我们使用 GPT 驱动非中国市场的产品和功能,但使用我们自主开发的模型驱动豆包。豆包只在中国提供。”赛斯在声明中称。
OpenAI 发言人尼克・菲利克斯(Niko Felix)发表声明,确认字节跳动的账户已被暂停。“所有 API 客户必须遵守我们的使用政策,以确保我们的技术被用于好的一面。虽然字节跳动很少使用我们的 API,但我们在进一步调查期间已暂停了他们的帐户。如果我们发现他们的使用不符合公司政策,我们将要求他们做出必要的改变或终止他们的账户。”菲利克斯表示。
字节回应被OpenAI“拉黑”:年中已停止使用GPT训练模型
北京时间2023年12月16日上午,科技媒体Command Line作者Alex Health的一篇文章,将OpenAI对字节跳动的控诉摆到了台前。这篇“檄文”中,字节被指控在大语言模型开发项目Project Seed中,几乎每个阶段都在秘密使用OpenAI的模型API来训练和评估模型。“参与的员工们对此心知肚明。”Alex Health声称自己在字节的沟通平台飞书上亲眼所见,员工讨论如何通过数据脱敏来粉饰证据,“滥用非常普遍,以至于Project Seed的员工经常达到访问API次数的上限。”
这场控诉的结局是,OpenAI禁止了字节跳动的账户。OpenAI发言人Niko Felix通过Alex Health发表了声明:
所有 API 客户都必须遵守我们的使用政策,以确保我们的技术得到良好利用。虽然字节跳动对我们 API 的使用很少,但我们在进一步调查期间已暂停了他们的帐户。如果我们发现他们的使用不遵守这些政策,我们将要求他们进行必要的更改或终止其帐户。

OpenAI 发言人 Niko Felix的声明。
所谓的“Seed”,是字节在2022年末就启动的基础大语言模型开发项目。该项目下有两个主要产品,一个是已在国内推出的聊天机器人“豆包”,一个则是正在开发中的、计划通过火山引擎对外提供服务的机器人平台。
一名业内人士对36氪表示,国内厂商用国外主流模型的API先试水业务、训练模型的情况并不少见:“先用先进模型把业务跑起来,等自己的模型训练能力达到标准再进行替换。”
而多名知情人士则向36氪透露,目前字节跳动的模型业务比距,无论是产品项目Flow,还是大模型项目Seed,都有国内海外业务两手抓的打算。由于政策规定,国内业务将采用字节自主研发的模型,而海外业务,将先采用国外厂商的模型API服务。
在OpenAI的服务条例中,确实存在竞争保护相关的内容。为了防止客户使用OpenAI的服务开发竞品,OpenAI对客户的使用范围做了严格的规定:只允许开发非商用的用于数据治理的AI模型,或者用于微调OpenAI对外服务的模型。

OpenAI的服务条例。
“拉黑”风波后,字节跳动发言人Jodi Seth在当日也快速做出回应。她表示,GPT生成的数据在Project Seed早期被用于标注模型,并在今年年中左右从字节跳动的训练数据中删除:
字节跳动获得了微软使用GPT API的许可。我们使用GPT为非中国市场的产品和功能提供动力,但使用我们的自我发展模型为豆包提供动力,豆包仅在中国可用。
这则声明承认了字节存在用GPT生成的数据训练模型的行为,但这个行为发生在OpenAI设定服务条例之前。可见的是,OpenAI最早一版服务条例发布于2023年8月28日,而字节声称在年中前已经停止将GPT生成的数据应用于训练过程。
OpenAI的第一版服务条例更新于2023年8月。
字节回应的另一个重点,则是强调GPT的API服务是通过微软云服务Azure,而非从OpenAI直接获得。换言之,OpenAI的“拉黑”,显得越俎代庖。
不过,即便是微软Azure,也拥有与OpenAI类似的竞争保护条款:“客户不得使用且不允许第三方使用微软生成式人工智能服务创建、培训或改进(直接或间接)类似或具有竞争性的产品或服务。”
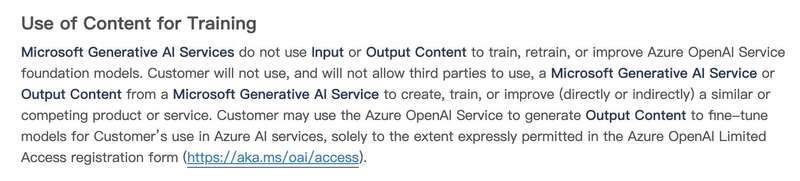
微软Azure生成式人工智能服务条款
如今,不少人都在等待微软Azure的回应。对海外AI业务依赖于国外厂商API的字节而言,微软的态度将至关重要。


