今天中午,英特尔正式发布了新一代移动芯片,自此,i3,i5,i7将从笔记本上抹去,取而代之的是Ultra系列。
Ultra5系,Ultra7系,Ultra9系将成为区分英特尔处理器强弱的新参考。
这Ultra是不是听起来很厉害?并且根据英特尔官方说法,这是它们40年来最大的改变。
但实际测试下来,你会发现在CPU能力上,这一代Ultra真的Ultra不起来……
01 新Ultra为何打不过老i7
在Ultra芯片上,英特尔首次把不同功能模块拆开,然后按照不同的制程将它们制作出来,最后如拼图一样,把这些模块凑在一起。
这次拆开的有4类功能模块——计算模块,SoC模块,图形模块,IO模块。
其中计算模块和图形模块很容易理解,就是以前的移动处理器中的CPU和GPU,SoC模块的“成分很复杂”,其中有2个功耗很低的超小核,负责AI计算的NPU,还有内存控制器。
IO模块负责处理器的一切外部沟通,像USB,WiFi,蓝牙,网络,PCI-e等等。
四个模块的功能不同,采用的工艺制程也有差距。计算模块(CPU)采用了英特尔最新的7nm节点(官方称为Intel 4),图像模块(GPU)采用了台积电的5nm节点,SoC和IO则是台积电的6nm的工艺。
写稿的时候,国内的发布会还在进行,我简单翻了下英特尔国外的宣传资料,发现在CPU部分,最新的Ultra7旗舰型号Ultra 7 165H在单核性能上竟然打不过上一代的低压版i7,在多核方面,也仅仅超过8%。相比老对手AMD,领先的也不是很多。
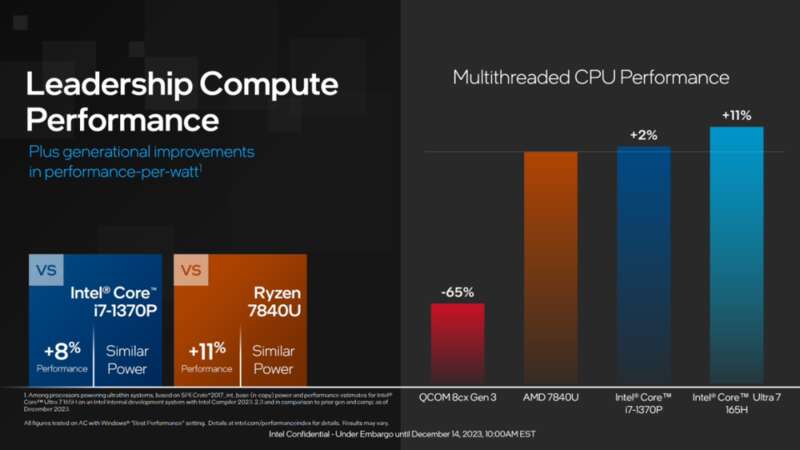
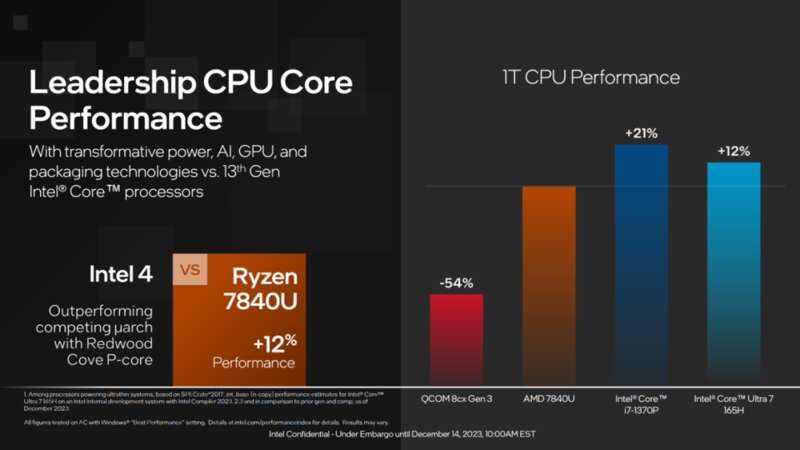
这是什么情况?工艺从10nm(官方称intel7)升级到7nm,性能几乎没有增长,牙膏厂又开始挤牙膏了?
还真不一定,如果大家仔细观察过最近几年芯片的产业,会发现,从AMD,Intel到苹果和高通,这些巨头们发布的新芯片的提升都没像前些年那样巨大了。
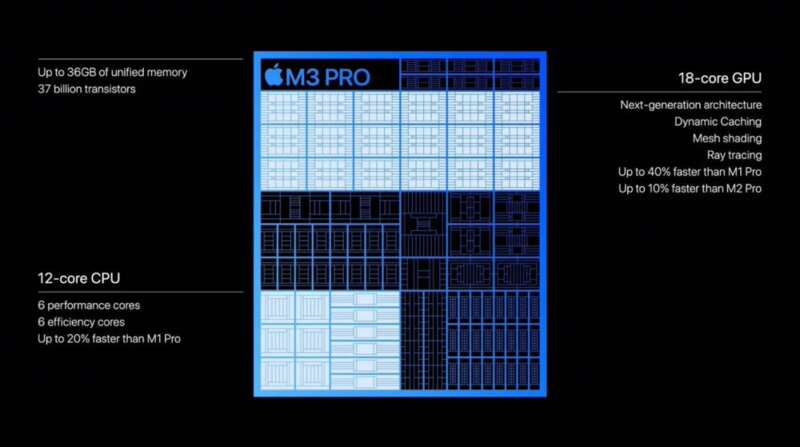
以苹果举例,无论是手机上用的A系列处理器,还是笔记本用的M处理器,在更新时,经常会与上上代做对比。比如苹果最近发布的M3 Pro,发布会上CPU对比部分,只出现了上上代的产品M1 Pro。
再来看看另外一组数据,还是苹果,只不过这次聚焦到它手机上用的A系列处理器, 从A6开始直到A9,每一代在制程上都有着提高,但从A10开始,制程不再是每年递进,而是两年一换。
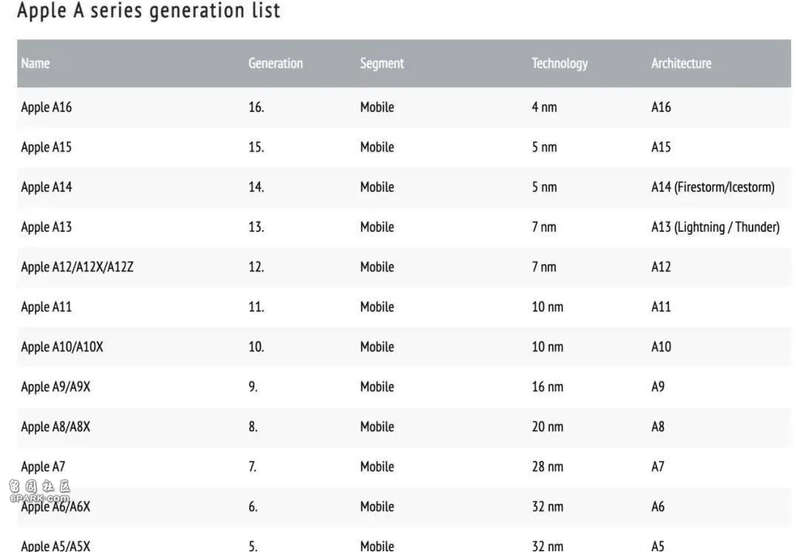
这些都在说明,在CPU方面,人类已经很接近极限了。单纯靠制程拉升晶体管数量的时代正在离我们远去。
02拯救芯片的救世主?
造成这种局面的原因有两个:
其一,随着越来越逼近1nm这个极限,目前的芯片技术储备已经见底,想要造出更小的晶体管,需要在许多学科方面都有突破。
在实际生产中,生产先进制程的芯片越来越困难。以苹果用到的台积电3nm工艺来说,需要多次打磨,不停的优化,才能达到具有最高良率的N3X节点。按照N3B,N3E,N3P,N3X的路线来看,苹果所用的N3E还远不是3nm的最佳性能。
其二,制程先进带来的副作用还体现在费用上,之前说过的M3系列芯片,在流片试产的时候,苹果向台积电支付了10亿美元!当然,各位老爷可能觉得这点钱对于三万亿市值的苹果来说没什么,但别忘了,这些钱最终都是转嫁到消费者头上的。
苹果也可以直接给台积电一万亿,直接采用良率更低的2nm,甚至是1nm的制程工艺来提升CPU性能,但那时候,可能一台笔记本就要十万了。毕竟布鲁斯韦恩还是少数人。

所以在CPU方面,以后应该比较难看到以前那种,年年都有爆炸式提升的情况了。
难道就没有什么“超级英雄”能拯救芯片行业了吗?
答案是肯定的,它就是Chiplet。
Chiplet解释起来很简单,就是把众多的小芯片通过某种技术,连接在一起,形成一个大芯片。
这次的英特尔Ultra系列就是这种技术的产物。虽然CPU部分提升不高,但它把自家独立显卡的核心拆出来,做成小芯片,放在了这代Ultra中。
所以Ultra的GPU能力得到了2倍的提升,基本上追平了目前最强核显——AMD的780M。有了Chiplet这个思想,英特尔还做出一些很有意思的事情,比如在SoC模块中塞入了两个更低功耗的“超小核”,在处理看视频,简单浏览网页这种低功耗的任务时,只会调动这两颗超小核而不是CPU模块,从而提高了整体的续航。
就在发稿前,我看了下相关的测评,Ultra的CPU性能可能没有涨,但是续航是实打实的有提升。
在经济性上,Chiplet也有很好的表现。
首先,开发人员不需要花费很大的力气把所有的东西都设计在一个芯片上,大大降低了研发的难度和周期。比如这次的Ultra为了跟上AI时代,在SoC模块上加入了大量的NPU。
其次,采用不同制程可以为节约成本,如前面提到过的,这次Ultra的CPU模块采用自家的最新的工艺,其他的使用台积电的5nm和6nm工艺。
当然,Chiplet对于芯片的算力提升也有帮助,像苹果的M2/M1 Ultra系列芯片,就是把两块M1/2 Max芯片结合在一起,实现了算力的提升。
我国之前上了实体清单的壁仞科技的BR100计算卡,也是通过两块芯片在内部链接,实现了算力全球第一的壮举。

那么,Chiplet实现起来难么,会是我们在弯道上超车的一个机会么?
03 弯道超车的机会来了?
之前大家都把所有的功能集成在一个芯片上,是因为数据这样传输起来最快。一旦把芯片隔开,在集合,如何实现它们之间数据的高速传输就变成了难以解决的问题。
直到最近10年,高级封装技术的出现才解决这个问题。在芯片之间利用硅片链接,然后芯片通过自身的小凸起和硅片链接,从而实现数据的高速传输。
乍听起来和大家日常把CPU插在主板上并没有什么区别,但实际上,抛开芯片只有几毫米不说,上面的小凸起只有十几微米大小,还要保证几百,甚至上千个组成的小凸起位子不出错,是非常困难。

除了芯片,硅片上也要做出穿孔和导线来保证互联,这一系列操作后。还需要在封装到普通的PCB板子上,复杂的工艺也就导致了,目前世界上只有三家公司能很好的完成先进封装。
它们就是台积电,英特尔和三星。除了上述的2.5D封装,HBM内存所采用的3D封装技术,也是这三家应用的最好。
根据之前查阅的研报来看,在封装方面,我们还处在相对落后的局面,不过在先进封装的测试阶段,许多国内的公司在国际上已经创出一些名堂来了。
最近也有令人欣慰的消息传来,国内的兆芯发布的新一代KX-7000系列处理器就是采用了Chiplet的技术,实现了CPU性能2倍的提升,GPU性能4倍的提升。除此以外,根据我查阅的资料来看,国内也有几个公司掌握了不错的封装技术,但为了避免一些不必要的麻烦,就不说它们的名字了。
日拱一卒,功不唐捐
在摩尔定律日益放慢的今天,越来越多的芯片大厂转向了Chiplet这条路,通过HBM,Ultra这样的案例来看,Chiplet的确是一个更为经济的提升算力的办法。
同时,制程的放缓,也给我们带来赶超的机会。虽然在封装方面,我们还有许多路要走,但相较于制程上的追赶,封装这条路更容易一些。只要大家的心态放平,正视差距,努力追赶,很快会有很多关于的Chiplet以及封装的好消息传来。


