AI胃口太大,人类的语料数据已经不够吃了。
来自Epoch团队的一篇新论文表明,AI不出5年就会把所有高质量语料用光。
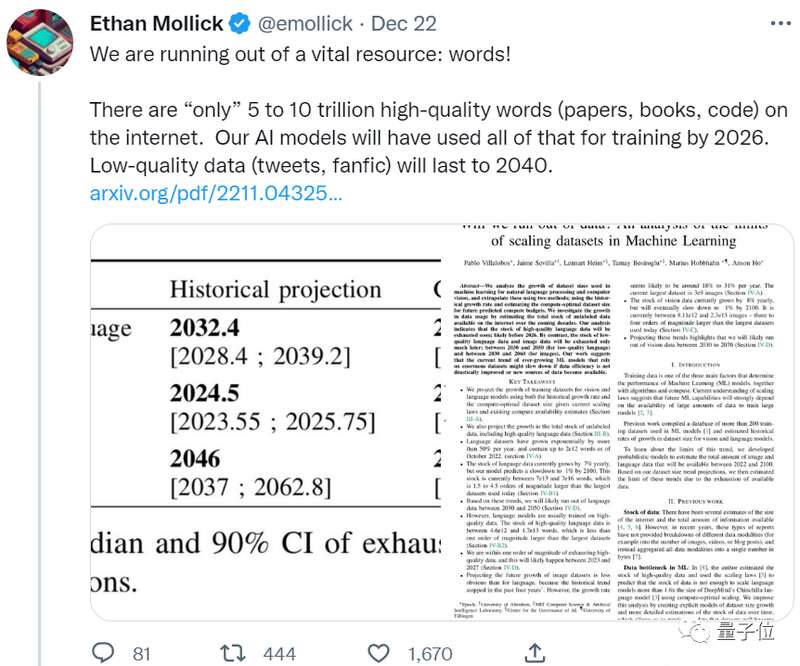
要知道,这可是把人类语言数据增长率考虑在内预测出的结果,换而言之,这几年人类新写的论文、新编的代码,哪怕全都喂给AI也不够。
照这么发展下去,依赖高质量数据提升水平的语言大模型,很快就要迎来瓶颈。
已经有网友坐不住了:
这太荒谬了。人类无需阅读互联网所有内容,就能高效训练自己。
我们需要更好的模型,而不是更多的数据。
还有网友调侃,都这样了不如让AI吃自己吐的东西:
可以把AI自己生成的文本当成低质量数据喂给AI。

让我们来看看,人类剩余的数据还有多少?
文本和图像数据“存货”如何?
论文主要针对文本和图像两类数据进行了预测。
首先是文本数据。
数据的质量通常有好有坏,作者们根据现有大模型采用的数据类型、以及其他数据,将可用文本数据分成了低质量和高质量两部分。
高质量语料,参考了Pile、PaLM和MassiveText等大型语言模型所用的训练数据集,包括维基百科、新闻、GitHub上的代码、出版书籍等。

低质量语料,则来源于Reddit等社交媒体上的推文、以及非官方创作的同人小说(fanfic)等。
根据统计,高质量语言数据存量只剩下约4.6×10^12~1.7×10^13个单词,相比当前最大的文本数据集大了不到一个数量级。
结合增长率,论文预测高质量文本数据会在2023~2027年间被AI耗尽,预估节点在2026年左右。
看起来实在有点快……
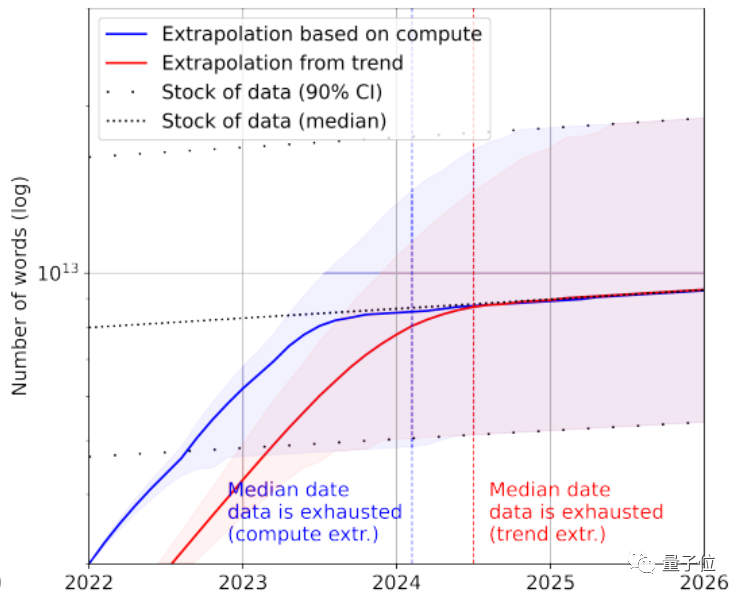
当然,可以再加上低质量文本数据来救急。根据统计,目前文本数据整体存量还剩下7×10^13~7×10^16个单词,比最大的数据集大1.5~4.5个数量级。
如果对数据质量要求不高,那么AI会在2030年~2050年之间才用完所有文本数据。
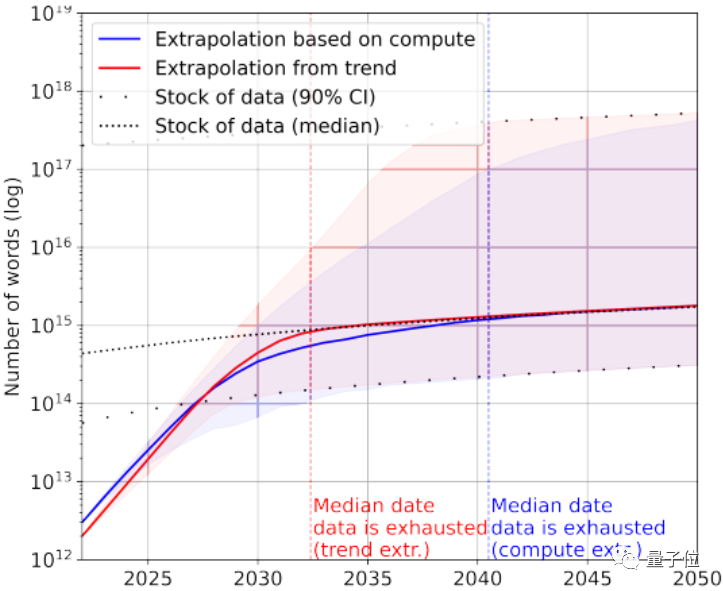
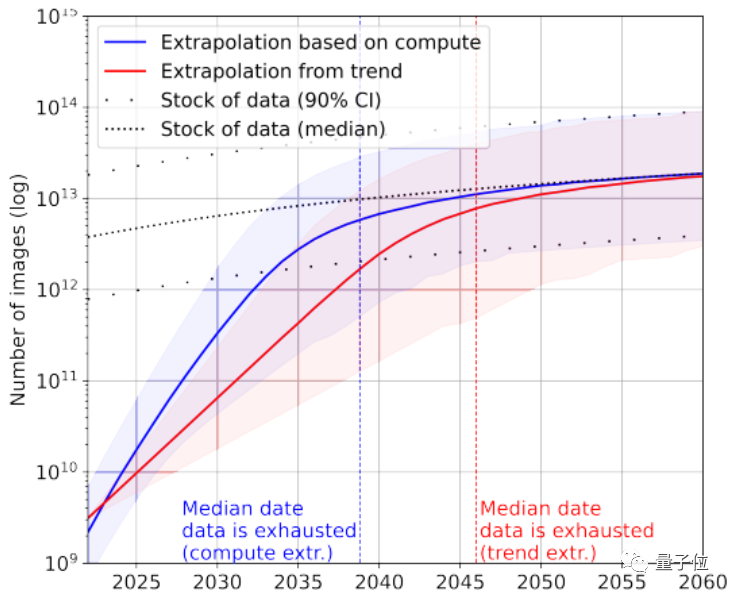
再看看图像数据,这里论文没有区分图像质量。
目前最大的图像数据集拥有3×10^9张图片。
据统计,目前图片总量约有8.11×10^12~2.3×10^13张,比最大的图像数据集大出3~4个数量级。
论文预测AI会在2030~2070年间用完这些图片。
显然,大语言模型比图像模型面临着更紧张的“缺数据”情况。
那么这一结论是如何得出的呢?
计算网民日均发文量得出
论文从两个角度,分别对文本图像数据生成效率、以及训练数据集增长情况进行了分析。
值得注意的是,论文统计的不都是标注数据,考虑到无监督学习比较火热,把未标注数据也算进去了。
以文本数据为例,大部分数据会从社交平台、博客和论坛生成。
为了估计文本数据生成速度,有三个因素需要考虑,即总人口、互联网普及率和互联网用户平均生成数据量。
例如,这是根据历史人口数据和互联网用户数量,估计得到的未来人口和互联网用户增长趋势:
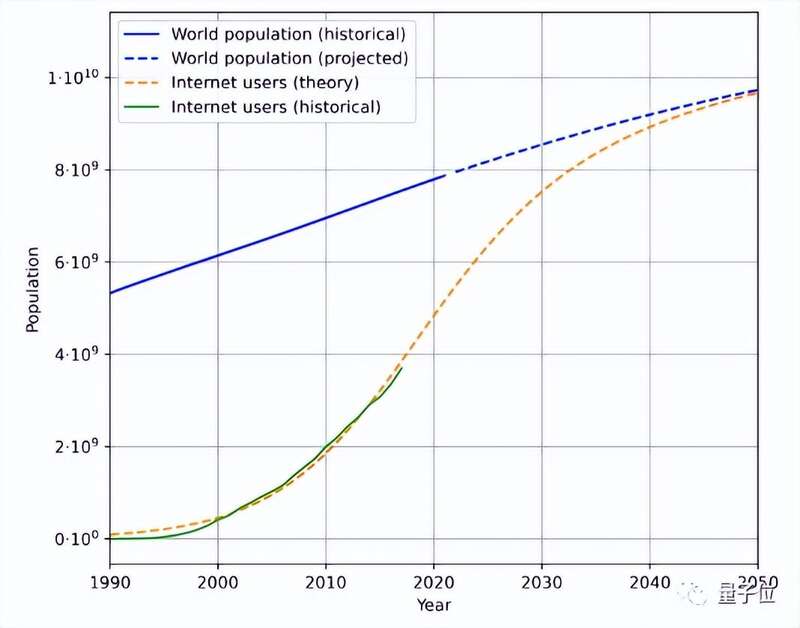
再结合用户生成的平均数据量,就能计算出生成数据的速率。(由于地理和时间变化复杂,论文简化了用户平均生成数据量计算方法)
根据这一方法,计算得出语言数据增长率在7%左右,然而这一增长率会随着时间延长逐渐下降。
预计到2100年,我们的语言数据增长率会降低到1%。
同样类似的方法分析图像数据,当前增长率在8%左右,然而到2100年图像数据增长率同样会放缓至1%左右。
论文认为,如果数据增长率没有大幅提高、或是出现新的数据来源,无论是靠高质量数据训练的图像还是文本大模型,都可能在某个阶段迎来瓶颈期。
对此有网友调侃,未来或许会有像科幻故事情节一样的事情发生:
人类为了训练AI,启动大型文本生成项目,大家为了AI拼命写东西。
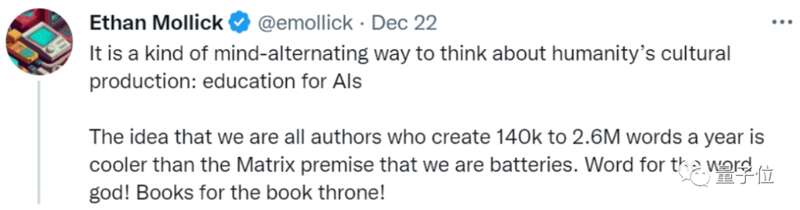
他称之为一种“对AI的教育”:
我们每年给AI送14万到260万单词量的文本数据,听起来似乎比《黑客帝国》中人类当电池要更酷?
你觉得呢?
论文地址:
https://arxiv.org/abs/2211.04325
参考链接:
We are running out of a vital resource: words!
There are “only” 5 to 10 trillion high-quality words (papers, books, code) on the internet. Our AI models will have used all of that for training by 2026. Low-quality data (tweets, fanfic) will last to 2040. https://t.co/hm1EaJ6Enu pic.twitter.com/PNsyUbPhBZ
— Ethan Mollick (@emollick) December 22, 2022


