春节期间,国产大模型 DeepSeek-R1 横空出世,证明了用更低的成本、更少的算力需求,就可以实现世界一流的模型性能水平。
R1 的出现似乎打破了大模型 “ 烧更多的钱买更强的芯片,换来更优性能产品 ” 的传统路径。1 月 27 日,英伟达股价单日下跌近 17% 。
不过,在人类通往 AGI 的路上,算力真的没那么重要了吗?
谷歌、微软、Meta和亚马逊这硅谷四个科技巨头可能并不这么想。
从 1 月 30 日起至今,这四家公司接连发布了自己的财报,而在最新的财报中,他们都不约而同的提到:2025 年,要花更多的钱来布局算力。
谷歌母公司 Alphabet 对 2025 年的资本开支目标为 750 亿美元,相比 2024 年增加了 42% 。谷歌表示,在 2024 年四季度,他们发现人们对 AI 产品有非常强劲的需求,以至于需求超过了他们的可用容量。因此,他们将努力解决这一问题,确保他们有更多容量 —— 也就是花钱搞更多算力。
微软则提到 2025 财年( 财年截至 6 月份 )将在人工智能数据中心上投入 800 亿美元,原因也与谷歌相同 —— 市场需求持续高于他们的可用容量,需要扩充。
微软还在电话会中表示,这样的投入他们甚至还是保守了的,因为 “ 不能一次买太多,因为摩尔定律使硬件每年都会有性能提升,一下子买太多会亏,要把握好节奏。”
Meta 方面,2025 年的资本开支预算是 650 亿美元,相较于 2024 年增长了 66%,扎克伯格表示:“ 我仍然认为,从长远来看,大力投资资本支出和基础设施上将是一种战略优势。也许我们会在某个时刻得出不同的结论,但现在还为时过早。此时此刻,我会赌注于,能够构建出这种基础设施将成为我们的一大优势。”
亚马逊则是在最新一季的电话会中提到 2025 年的资本开支将达到约 1000-1050 亿美元,比去年的 830 亿美元增加了 24%,亚马逊首席财务官 Brian Olsavsky 在财报电话会上表示,这笔资本支出的 “ 绝大部分 ” 将用于AI和云服务AWS。
四巨头都在算力上继续增加投入,并不是因为看不上 DeepSeek,反而是非常认同 DeepSeek。
亚马逊首席执行官 Andy Jassy 表示,推理成本的减少,不意味着总支出会下降,“ 实际情况并非如此,我们在云计算领域经历过类似情形 ”。
而微软的 CEO 此前也在 X 上发博转发了维基百科的 “ 杰文斯悖论 ” 词条来表示他的态度。
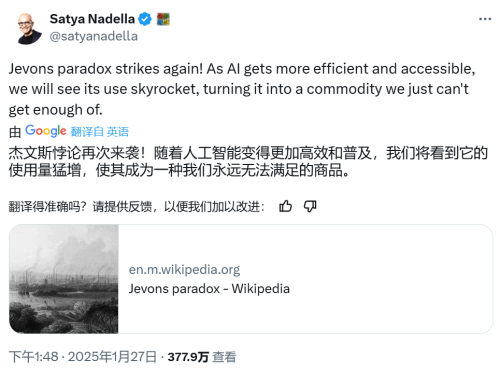
杰文斯悖论的核心逻辑是:技术提高资源使用效率后,可能会因人类行为的改变或市场反馈,导致总消耗量不降反升。
举一个非常简单的例子:随着汽车技术的不断提升,发动机的热效率不断提高,变得越来越省油,但由于效率提高使得用车成本降低,人们会买更多的车、开更远的路,最后反而使得石油的消耗量变大。
同理,在 AI 世界里,DeepSeek 就是那台效率更高的发动机,而算力就是汽油,单辆车的耗油量变低了,整个市场的汽油用量却会增多。
要知道,DeepSeek-R1 虽然训练成本低,但也是遵循 Scaling Law ( 规模扩展法则 )的。
在 Scaling Law 之下,我们可以简单粗暴地把模型表现和算力需求看成一个 y=ax 的正相关函数,过去的模型的斜率 a 相对较小( 效率相对较低 ),模型表现虽然会随着算力的加大而变得更好,但是增长较慢。DeepSeek 的斜率 a 则相对较大( 效率相对较高 ),模型表现随算力加大而表现变得更好的速度会更快。
在这种情况下,你会因为效率更高而减少投入吗?你大概率会因为效率更高而加大投入。
所以,与其担心算力过剩,我们似乎更应该关心的是算力和效率我们都有,但是已经没有优质数据可以用来训练了。
同样还是拿汽车来举例子,当汽车的油耗( 模型效率 )和汽油( 算力 )都充沛的情况下,大家都买了车,最后却发现出行速度没办法进一步提升了,因为路( 优质训练数据 )不够了,堵车了。
或许在未来,数据标注师会越来越少,世界会冒出来很多 “ 数据生产师 ”,他们每天坐在格子间里,绞尽脑汁创造能提高模型性能的优质数据。
Advertisements