英伟达股价下跌的核心原因是,投资者担忧大模型算力“大力出奇迹”模式被颠覆,英伟达的算力优势将极大被削弱。
美国东部时间1月27日,英伟达(NASDAQ: NVDA)股价单日下跌16.9%。截至收盘时,英伟达股价118.58美元,总市值2.9万亿美元,单日蒸发5900亿美元。英伟达大跌同时引发了纳斯达克的震荡。当日,纳斯达克指数下跌3.1%。
英伟达是全球AI(人工智能)芯片巨头,目前也是全球市值第三的科技企业,仅次于苹果(3.5万亿美元)、微软(3.2万亿美元)。
英伟达在数据中心AI芯片市场占据垄断地位。市场调研机构Jon Peddie Research(JPR)2024年12月数据显示,截至2024年三季度,英伟达在全球GPU(图形处理器,目前是数据中心AI芯片的主流选择)市场份额高达90%。
2024年,英伟达的业绩因为科技公司大规模采购AI芯片高速增长。2024年前三季度,英伟达总营收911.7亿美元,同比增长159.4%。
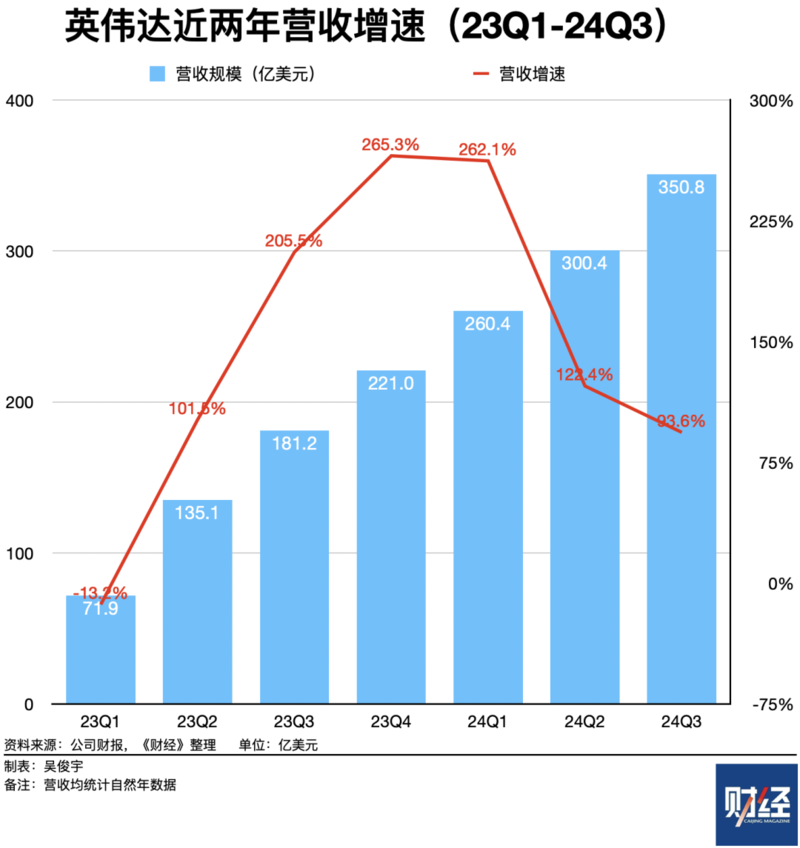
英伟达股价下跌的核心原因是,投资者担忧大型科技公司在2025年会削减AI支出,大规模减少采购英伟达芯片。中国AI创业公司DeepSeek(深度求索)的爆火被认为是这种担忧情绪的导火索。
DeepSeek近期发布了DeepSeek-V3、DeepSeek-R1两款开源大模型。DeepSeek宣称,可以用更小的算力集群、更低的算力成本训练出和AI明星创业公司OpenAI旗下GPT-o1性能接近的大模型。
这意味着——英伟达的智能算力芯片在全球AI发展道路上,可能不那么被大量需求了。
OpenAI在2023年春节期间拉开了新一代人工智能的时代帷幕,也打开了英伟达的起飞路径。现在,新的转折点可能已经到来了。

“大力出奇迹”模式被挑战
英伟达的高增长主要来自拥有云计算或大模型业务的科技公司(如微软、亚马逊、谷歌、甲骨文、字节跳动、阿里、腾讯、百度等)。
2023年以来,中美科技公司对大模型的发展共识是,新一代人工智能产业发展需要“大力出奇迹”——只有拥有足够的芯片、足够的资金才能支撑大模型迭代以及商业化。因此,英伟达的高增长本质是由科技公司高昂的资本支出所支撑的(相关报道见《科技公司会一直为英伟达的高增长买单吗?》)。
一位中国科技公司战略规划人士对《财经》表示,字节跳动、阿里、腾讯、百度等大型科技公司,每年60%以上的资本支出都被用于投资算力,如采购芯片、服务器、租赁土地、建设数据中心,英伟达是最大受益者之一。
为采购英伟达的算力,英伟达最大的几个客户——微软、亚马逊、谷歌2024年前三季度资本支出分别是530亿美元、377亿美元、263亿美元,同比增长78%、51%、81%。中国科技公司资本支出增速甚至更高,如阿里、腾讯2024年前三季度资本支出分别是407亿元、402亿元,同比增长178%、153%。
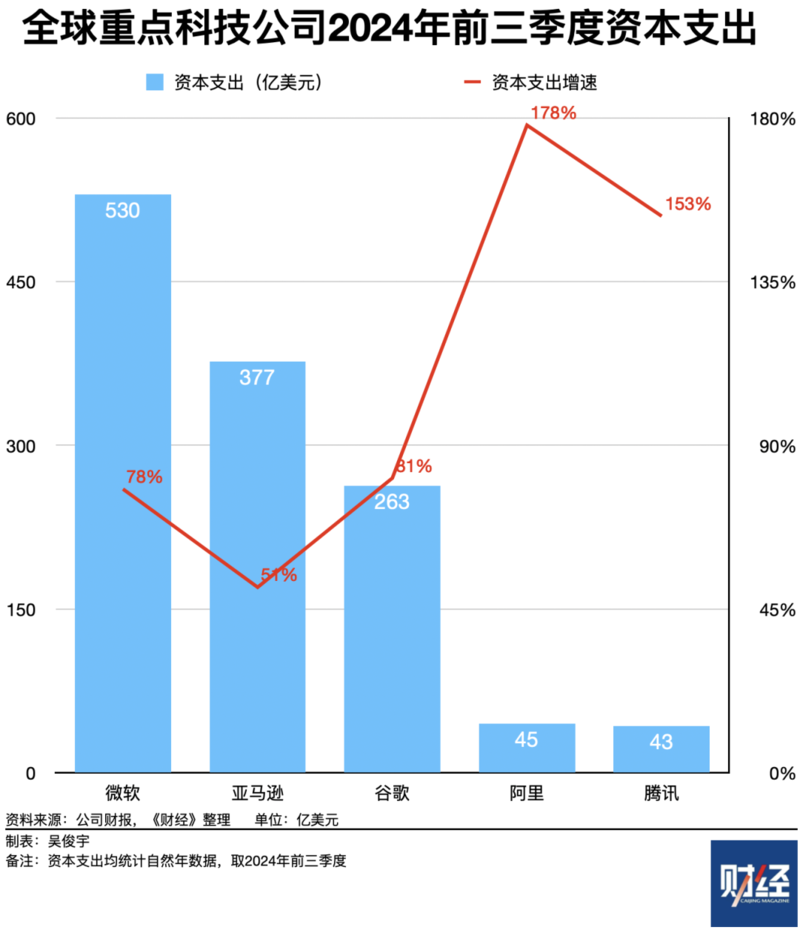
对中美科技公司来说,这种高强度的资本支出增速均是近五年的顶峰。科技公司资本支出增速通常在20%左右。科技公司资本支出经历增长高峰后,往往会在未来一段时间负增长。也就是说,英伟达长期维持100%甚至200%以上的高速增长是不现实的。英伟达将从高速增长回落到温和增长。
2024年9月,一位中国云厂商数据中心业务负责人和一位中国科技公司大模型业务负责人均表示,如此高强度的资本支出超出了很多从业者的预期,甚至可能有泡沫。
他们认为,2025年下半年是观察英伟达能否持续高增长的重要节点。科技公司的资本支出往往存在周期性波动。因为目前,微软、亚马逊、谷歌等公司均在财报电话会议中表示,2025年上半年资本支出还将维持高增长。但他们并未对2025年下半年的资本支出情况做出明确说明。一旦大模型落地进展不乐观,科技公司将迅速缩减资本支出,英伟达的收入增速也将随之下滑。
基于资本支出的周期性波动,投资者一直在关注英伟达的高增长到底能持续多久。投资者对英伟达担忧情绪始于2024年二季度。当时,英伟达2024年二季度财报电话会,有投资者提问,“客户对AI芯片的投资回报率,以及资本支出可持续性争论相当激烈,英伟达要如何回答该问题?”当时,英伟达创始人黄仁勋没有直接回应,他只是解释——更快的计算速度会带来更低的能源消耗和更低的计算成本。
担忧情绪在近期进一步被放大——中国AI创业公司DeepSeek被一些投资者认为是这种担忧情绪的导火索。DeepSeek背后的母公司是幻方量化,这是一家总部位于杭州的量化基金。
DeepSeek近期发布了DeepSeek-V3、DeepSeek-R1两款开源大模型。该公司宣称,仅用2048张英伟达H800芯片(H100阉割版,英伟达针对美国商务部出口管制规则特供中国市场的芯片),以及550万美元(约合4亿元)就训练出了与OpenAI旗下GPT-o1(OpenAI旗舰模型)性能相当的模型,且推理算力成本仅为GPT-o1的1/30。
1月27日,美国总统特朗普在佛罗里达州迈阿密发表讲话时表示,DeepSeek的模型高效且经济,其出现是一种积极的发展,也给美国相关产业敲响了警钟。美国需要集中精力赢得竞争。
1月27日,微软首席执行官萨提亚・纳德拉在瑞士达沃斯世界经济论坛表示,DeepSeek的新模型令人印象深刻。尤其是在如何高效开发开源模型并进行推理计算方面,它的计算效率非常出色。我们应当非常、非常认真地对待来自中国的这些技术进展。
1月28日,OpenAI创始人山姆·阿特曼 (Sam Altman)在社交媒体上公开评论称,DeepSeek能够以低价算力提供这样的服务令人惊讶。他表示,OpenAI将暂停一些新的发布,拥有一个新竞争对手令他感到兴奋。
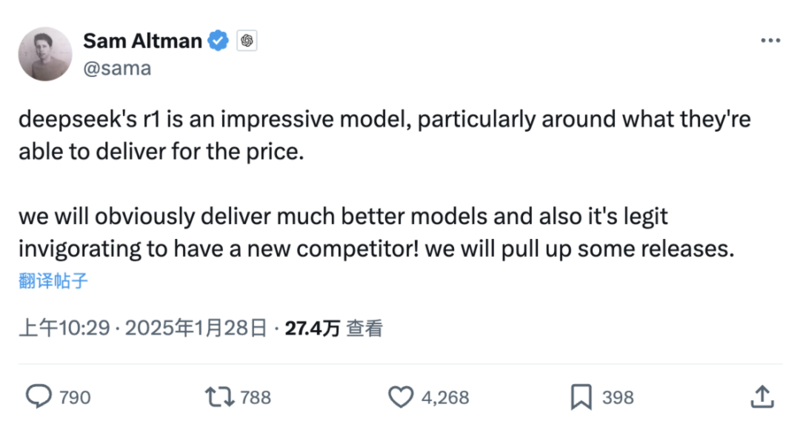
(图片来源:OpenAI创始人山姆·阿特曼社交媒体X)

英伟达能否继续增长?
美国投资者社区Seeking Alpha被广泛传播的一种解读是,DeepSeek加剧了美国投资者的恐慌,进而引发了英伟达股价的下跌。经过两年的疯狂堆砌算力之后,AI从业者正在思考——大模型除了“大力出奇迹”,是否还有其他技术路线?
目前,中国和美国科技公司训练一代大模型的成本均高达数千万美元甚至数亿美元。
一位中国头部科技公司大模型技术人士对《财经》表示,DeepSeek在模型结构上的确有创新,模型性能表现也接近GPT-o1。它采用的混合专家系统(MoE)、多头潜在注意力(MLA)技术,可以降低模型推理成本。但目前无法确认,它宣称的“仅使用了2048张英伟达H800芯片和550万美元训练成本”是否属实。
华尔街投资机构伯恩斯坦也对DeepSeek的实际开发成本产生了怀疑。该机构认为,DeepSeek公布的数字可能少于实际投入。该机构称,DeepSeek的模型看起来很棒,但不应被视为奇迹,市场目前的反应更多是恐慌情绪。特斯拉CEO(首席执行官)埃隆·马斯克甚至认为,DeepSeek实际拥有价值超过10亿美元的英伟达芯片。
虽然市场对DeepSeek路线的革命性存在质疑,但一个不争的事实是——由于美国对华芯片出口管制,科技公司一直在思考如何通过堆砌算力之外的其他策略提升模型性能。
过去两年,大模型的发展遵循着Scaling Law(OpenAI在2020年提出的定律,直译为“缩放定律”)——模型性能主要与算力规模、模型参数和训练数据三者相关。目前,中国科技公司一直在试图通过提升数据质量/数量、优化算法和架构的方式,降低训练及推理算力成本。
卡内基国际和平基金会的人工智能研究员马特·希恩 (Matt Sheehan) 认为,美国的出口管制实际上将中国公司逼入了绝境,迫使中国公司必须利用有限的计算资源提高效率,并认为未来可能会看到大量与计算资源匮乏相关的整合。
一种观点是,但如果DeepSeek披露的信息属实,那这意味着,科技公司对英伟达高端AI芯片的需求可能会减少,英伟达可能将难以维持高增长。摩根大通分析师桑迪普·德什潘德 (Sandeep Deshpande)指出,DeepSeek的低成本成功可能让投资者意识到人工智能投资周期被过度炒作。
一种对英伟达持乐观态度的观点是,大模型训练、推理成本下降,会进一步放大市场对英伟达AI芯片的需求。
一位美国科技产业投资人认为,DeepSeek的实际影响和可扩展性仍未得到证实。投资者抛售英伟达股票看起来像是过度反应。即使DeepSeek真如宣称的那样低成本,也只会进一步激发英伟达的市场需求。
另一位产业界人士对《财经》表示,从短期来看,DeepSeek确实会对英伟达等估值产生冲击,但是长期来看英伟达的优势在生态。这意味着只要AI技术还在发展,生态就会越来越重要,英伟达就能发展。
DeepSeek被争议的点是此前业内传闻DeepSeek事实上是中国少数拥有万卡储备的公司之一。一位曾经调研过DeepSeek的芯片投资人表示,在他看来,DeepSeek的优势确实是以较低的成本做出更好的效果,但这种成本可能不是外部传闻的低量级。
他认为,DeepSeek的另一个被外界忽略的特点是,虽然投入足够的计算资源,但没有设定明确的投入收益回报,这让其有更宽松的环境创新。
1月26日,英伟达声明称,DeepSeek在人工智能领域取得了卓越进展,是Test Time Scaling(TTS,即在推理阶段通过增加计算量来提升模型推理能力的一种方法)的绝佳范例。DeepSeek的成果展示了如何利用这一技术,借助广泛可得的模型以及完全符合出口管制规定的计算资源来创建新模型。
一举“干翻”英伟达!DeepSeek震惊世界,国产AI忽然这么强了?
最近几天,小雷都忙着置办年货、打扫家里卫生。好不容易有个摸鱼的空档,掏出手机想刷刷微博抖音,却发现所有社交媒体都被AI刷屏了。

图源:微博截图我怎么隐约记得,上一次掀起这种级别的讨论度的AI,是ChatGPT呢。2023年的春节,ChatGPT一夜爆红,掀起了大模型浪潮。
在2年后,2025年的春节,DeepSeek爆发,再度颠覆世界!
不仅在国内讨论度高,在国外也非常多人关注。昨天,DeepSeek就反超了ChatGPT,一举登顶美区AppStore免费App排行榜第一。

图源:微博截图
可能大家会问,DeepSeek凭啥在全球爆火?
大家都知道,现在的AI行业真的特别卷。很多豪得没道理的公司,都在争相把自己的业务做大、做满。AIGC视频工具、图像生成、智能音频助手......只要你想得到的功能,他们都想开发!而DeepSeek,深耕大模型研发战场。
2024年底,DeepSeek发布了新一代MoE模型DeepSeek V3。按照主流机构的测评,DeepSeek在很多方面表现和ChatGPT不相上下。在中文领域,本土的DeepSeek表现更胜一筹。在数学能力上,V3已明显领先其他开/闭源模型,包括Meta的 LIama,阿里的Qwen。
能力并不是它引起大众关注的主要原因。
V3发布的一个月后,1月20日,他们发布了震撼整个科技界的Deepseek R1模型。综合性能和o1不相上下不说,重点是整个模型的训练过程只花了557.6万美元。用的还是英伟达特供的阉割版低性能算力卡H800。
API价格也被打下来了!用远低于行业平均的价格,成为了AI价格战的“领头人”。

图源:Deepseek官网
在芯片封锁的情况下下,咱们中国人搞出了和同类不相上下甚至更先进的产品,而且我们用的钱更少。
美国的AI霸权,彻底被挑战了!
接下来,跟小雷一起看看DeepSeek的实战能力如何吧。
马上春节了,老板让小雷做个宣传海报,上面得带有咱们公司名字的藏头诗。押韵太难了,小雷挠破头都想不出来。问问大模型吧!
Deepseek V3给出的结果是“雷动九天迎新春,科峰登顶志凌云。技展宏图开盛世,蛇舞祥瑞福满门”。
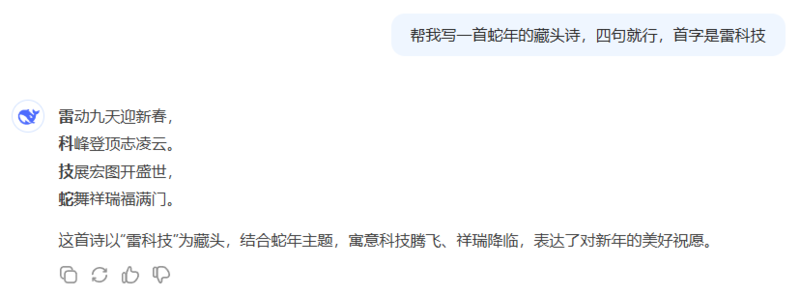
图源:DeepSeek
如果调用R1(深度搜索),人工智能的「思考过程」会毫无保留地展示出来。甚至你还能看到它给自己不断纠错、生成一版更好的内容。牛啊!
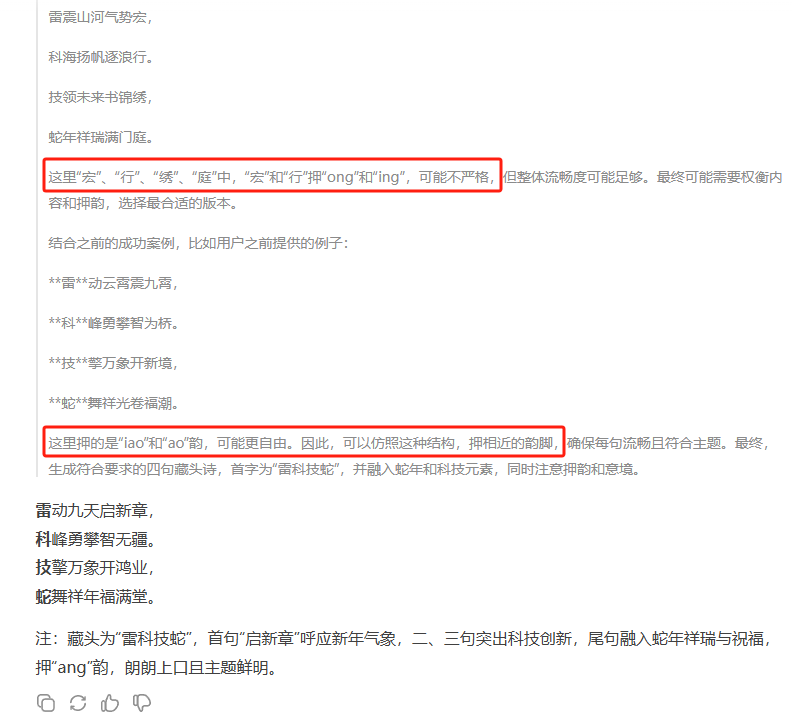
图源:DeepSeek
反观ChatGPT,给出的答案有点平平无奇。如何把中国的文化内涵发挥得更出色,还是得看中国的大模型。
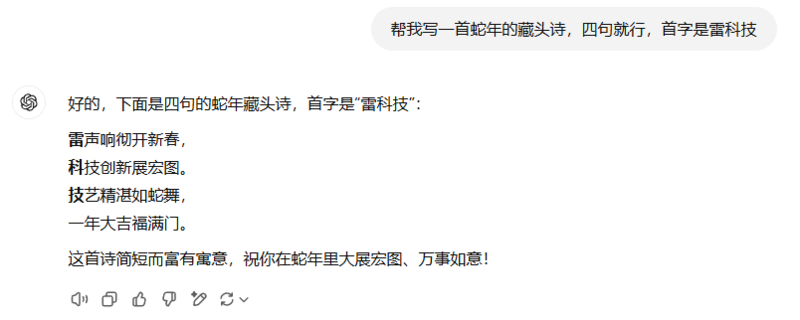
图源:ChatGPT
接着小雷扔了去年广东高考一道数学填空题给他们,DeepSeek的表现依然优秀,每一步骤都列得非常详细。

图源:DeepSeek
把同一个题目扔给豆包,给出的答案和DeepSeek的一样。反观ChatGPT,怎么跟标准答案不一样呢......

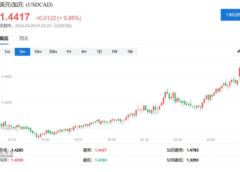
图源:ChatGPT昨晚,DeepSeek一夜“掀翻”了美国科技股。英伟达、台积电、博通、美光等明星股领跌,英伟达市值蒸发5000亿美元,跌没了一个腾讯。
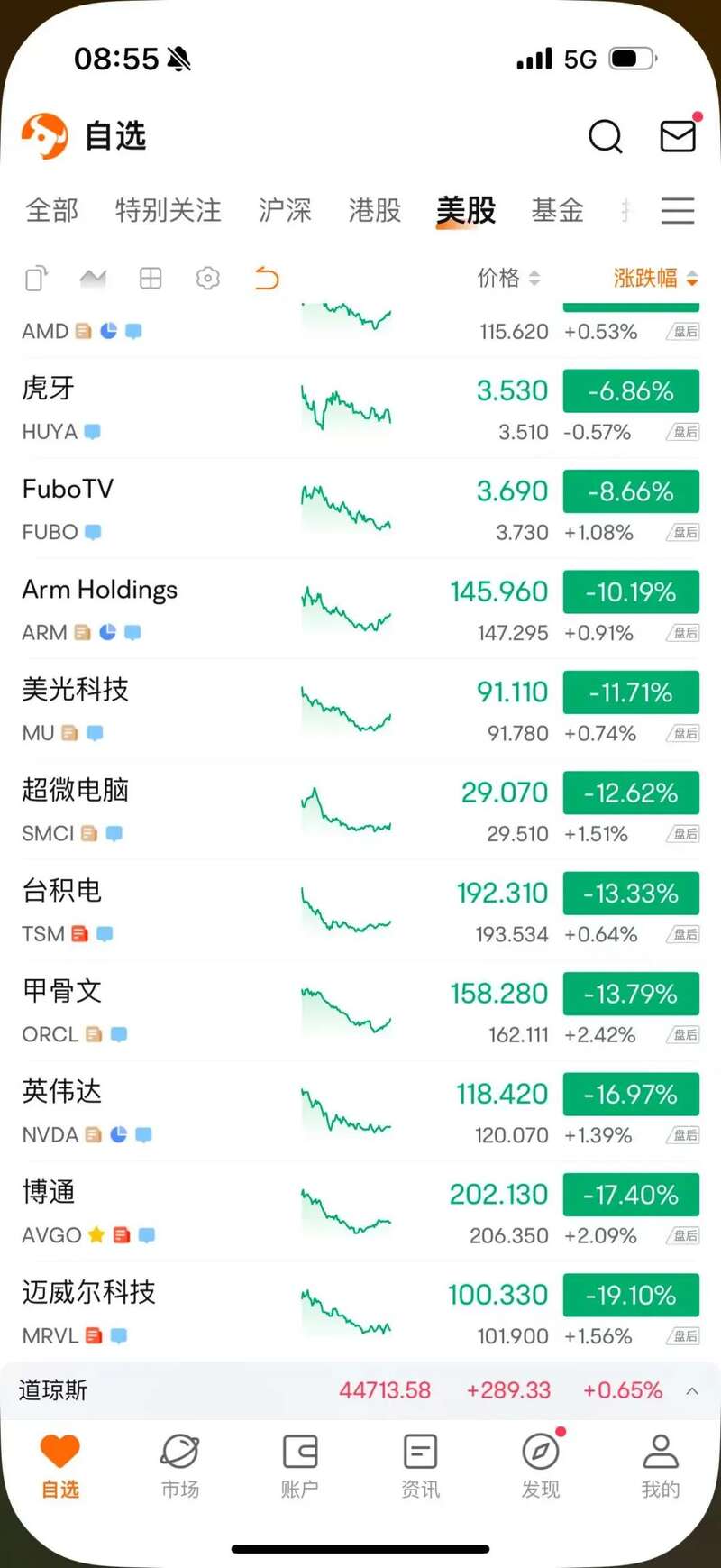
图源:富途
在国内外掀起一轮舆论狂欢后,1月28日凌晨,DeepSeek在GitHub发布了Janus-Pro多模态大模型,进军文生图领域。

图源:微博截图
不到200人的开发团队,仅用500多万美元的成本,直接碾压美帝。借用评论区一位老哥的话:见证历史了!相信大家都非常荣幸,能够见证国产高科技屹立世界之巅。
咱们总能弯道超车,给老外不一样的惊喜。这才是真正的“OpenAI”,DeepSeek牛!
Advertisements