“我们需要更大的GPU。”
当地时间3月18日,黄仁勋在英伟达2024 GTC大会上,宣布了英伟达新一代加速计算平台NVIDIA Blackwell,以及基于Blackwell GPU架构的双芯片GPU B200和超级芯片GB200。
Blackwell架构单GPU AI性能达到 20 PFLOPS,性能比上一代提高了5倍,而成本和能耗下降降低25倍。黄仁勋以训练1.8万亿参数的GPT模型为例(可能GPT-4的参数量)。同样以90天为训练周期,上一代Hopper架构的GPU至少要用8000个,功耗15MW,而使用Blackwell架构的GPU,只需要2000颗,功耗约4 MW。

Blackwell
作为全球加速计算市场的“老大”,英伟达今天的一切成功都建立在GPU上。
不过,从黄仁勋在GTC大会上的主题演讲来看,英伟达似乎并不希望外界只看到他们的GPU。在黄仁勋2个小时的主题演讲中,虽然Blackwell平台的发布是绝对主角,但他也把超过一半的演讲时间放在了GPU“周围”的技术上,包括:芯片设计、生产技术,生成式AI模型训练,数字孪生,以及具身智能等。
一直以来,英伟达都在强调自己是“人工智能时代领先的计算公司”,而不只是一家芯片或是硬件公司。在GTC上宣布的软件技术、AI训练技术、机器人技术等,也无不透露着“源于GPU,高于GPU”的味道。
软件是GPU的护城河
加速计算市场上并不乏性能与英伟达接近的GPU产品,然而英伟达真正的护城河其实来自GPU软件开发工具。
在Blackwell之外,英伟达公布了一系列与AI、GPU、机器人相关的创新软件应用,包括:
AI 模型和工作流微服务产品NVIDIA NIM(NVIDIA AI Microservices);企业级的 AI 软件平台NVIDIA AI Enterprise 5.0;用于机器人开发的仿真环境NVIDIA Isaac Sim;GPU 加速、性能优化的轻量级应用NVIDIA Isaac Lab;用于计算编排服务的工具NVIDIA OSMO;用于药物研发的微服务NVIDIA BioNeMo;用于基因组学分析的软件套件NVIDIA Parabricks;用于视频分析和智能视频管理的软件平台NVIDIA Metropolis等。
其中,NVIDIA NIM(NVIDIA AI Microservices)最为突出。
NIM是一系列集成AI模型和工作流的微服务,专为企业和开发者提供在生物、化学、影像及医疗数据领域构建和部署AI应用的高效、灵活方式。NIM的关键优势是其符合行业标准的API,便于开发者创建云原生应用。
目前,NIM 微服务以及开始在医疗影像领域推广。通过利用 NVIDIA 的 AI 技术,NIM 微服务可以帮助医疗专业人员更快速、更准确地分析和解释医疗影像数据,从而提高诊断的质量和效率。此外,NIM 微服务还可以用于药物研发,通过生成式化学模型和蛋白质结构预测模型,加速新药的发现和开发过程。
事实上,软件应用生态除了在AI等开发端支撑英伟达的GPU业务,在未来也有可能为英伟达走出一条新的增长曲线。
SaaS行业是公认的毛利更高、赚钱快,且软件、应用研发资产轻,不会像硬件生产那样受到供应链的制约,也没有生产、库存压力。
虽然英伟达的GPU借着AI的东风也能赚得盆满钵满,但增长速度相比不如爆发增长的OpenAI。而且如果只做GPU和算力生意,未来的发展空间,也难免会受到制造业自身增长缓慢属性的影响。
已经垄断了GPU生意的英伟达,自然不希望像AMD、Intel、高通那样,“躬耕”于芯片行业卷生卷死。对于英伟达来说,基于AI大模型、软件等向上再迈一层,不仅能巩固自己当下的行业地位,也能拓宽未来的赛道。
算力怪兽的关注点在通信
专为AI而生的Blackwell可以处理万亿参数规模的大语言模型(LLM)。每块GPU拥有2080亿个晶体管,采用专门定制的双倍光刻极限尺寸4纳米TSMC工艺制造,通过 10 TB/s的片间互联,将GPU裸片连接成一块统一的GPU。
与Blackwell平台一同推出的还有采用双芯片设计的新一代GPU B200,单GPU AI性能达到20 PFLOPS。B200配备192GB内存。以及基于B200的超级芯片GB200 ,通过900GB/s超低功耗的片间互联,将两个 NVIDIA B200 Tensor Core GPU 与 NVIDIA Grace CPU 相连。
虽然Blackwell的性能提升巨大,但今天的超大规模AI模型多数都需要多GPU并联计算。由此,GPU的连接性能,才真正体现了GPU在AI大模型训练和应用过程中的价值。
第五代NVIDIA NVLink提供1.8TB/s 双向吞吐量,可以使576块GPU之间实现无缝高速通信,满足更为复杂的大语言模型训练需求。
在云端模型部署方面,英伟达还推出了NVIDIA Quantum-X800 InfiniBand 和 Spectrum-X800以太网网络平台,提供了高达800Gb/s 的端到端吞吐量,大幅提高了AI和HPC分布式计算的可用性。
此外,英伟达还推出了6G研究云平台,以推动AI在无线接入网络 (RAN) 技术的应用。保证了端侧设备到云基础设施之间的链接,从而推动自动驾驶汽车、智能空间和沉浸式教育体验的发展。

英伟达全新网络交换机 - X800 系列。
与Blackwell架构一同宣布的,还有英伟达与主流服务器、云计算厂商的合作。AWS、戴尔、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉和XAI等预计都会在未来将加速计算服务器更新到Blackwell架构。
促进落地是英伟达的当务之急
在GPU硬件方面,英伟达在全球GPU市场中持续保持领先。Blackwell的性能比2年前的Hopper架构提升了5倍,比8年前的Pascal架构提升了1000倍。
黄仁勋在演讲中自豪地说:“摩尔定律是每10年提升100倍性能,过去8年里,我们提升了1000倍,我们还少用了2年。”
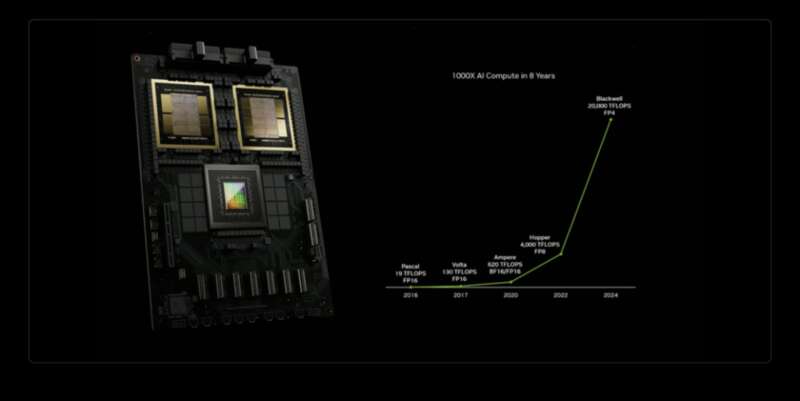
英伟达GPU性能八年提升1000倍
Blackwell一出,业界一片欢腾,很多人直呼:新摩尔定律诞生了。
相对于英伟达的用户,华尔街对英伟达的看法相对冷静。
刚刚过去的3月前几周,英伟达遭市场逼空,3月8日股价下跌5.55%。虽然华尔街对英伟达本届GTC表现乐观,市场普遍预测此次大会将帮助英伟达股票结束近期震荡走势。但是黄仁勋的主题演讲结束后,英伟达夜盘表现不佳,次日开盘股价亦未见起色。
这主要是因为GTC上公布重磅新品,对于市场来说基本都在预期之内。其实对于英伟达来说,不管是8年前的Pascal还是今天的Blackwell。1-2年一次的GPU架构的升级早已经是顺理成章的技术迭代,时至2024年,推出Blackwell在英伟达来说是一个“渐进式创新”的必然结果。
另一方面,对于如今的市场来说,随着GPU技术的迭代,算力快速增长很可能会大幅压缩英伟达的增长空间。
方舟投资首席执行官、知名投资人“木头姐”凯西·伍德(Cathie Wood)在3月7日致股东的一封信中对英伟达未来可能面临的竞争压力发出警告,并将其与思科在1997至2000年期间股价经历的“抛物线”进行比较。
伍德认为,如果AI公司、软件公司在应用层面一直见不到收益的话,很可能会停止增加在GPU建设方面的投入。
只是循序渐进地提升GPU性能,显然不能保证英伟达业务的长期增长。英伟达需要给客户提供更多围绕GPU构建业务能力的工具。英伟达大概也早就认识到了这一点。
在传统的GPU图形渲染方面,英伟达重点向客户推广工业数字孪生应用和工作流创建平台Omniverse。本次GTC,也宣布了最新的NVIDIA Omniverse Cloud API,用以帮助开发者将 Omniverse 技术集成到他们的设计和仿真工具中。
英伟达还宣布了与西门子、达索系统、Ansys、楷登软件、新思科技等主流工业软件厂商的进一步合作。
在AI方面,本次GTC上英伟达公布了一款人形机器人基础模型NVIDIA Project GR00T。可以支持通过语言、视频和人类演示来学习动作和技能,为机器人技术的 AI 应用提供了新的可能。Project GR00T与前段时间Figure推出的使用OpenAI大脑控制的机器人有些异曲同工。Project GR00T是一个多模态的人形机器人通用基础模型,可以使机器人通过观察人类行为来模仿动作,从而快速学习协调、灵活性等技能。
除此之外,英伟达一直着力打造的机器人开发和仿真环境Isaac平台此次也升级加入了生成式 AI 基础模型和仿真工具,以及针对机器人学习和操作的优化工具。
英伟达带来最强AI芯片,资本市场却泼了点冷水

在股价上呈现追赶苹果之势的英伟达,先在产品上学了苹果一招。
北京时间3月19日对外发布的B200 GPU芯片上,英伟达首度采用了芯片封装设计,即在一个大芯片上集成了两个相同制程工艺的小芯片。
如何在无法提升制程工艺的前提下,实现芯片性能的进一步突破?苹果在2022年的MI Ultra芯片上率先给出了解题思路——将两个M1 Max芯片组合在一起,构成了MI Ultra,在同样制程工艺基础上实现了性能的提升。

被黄仁勋视为地表最强AI芯片B200发布后,包括微软执行董事长兼首席执行官萨提亚·纳德拉、Alphabet和谷歌首席执行官桑达尔·皮查伊、亚马逊总裁兼首席执行官安迪·贾西等一众云服务厂商大佬纷纷站台支持。
特斯拉及xAI首席执行官埃隆·马斯克也不吝溢美之词:“当下的AI领域,英伟达硬件无可比拟。”
在生成式AI这股火爆趋势中充当“AI军火商”的英伟达,凭借此前发布的A100、H100等GPU,股价自2023年迎来暴涨,总市值相继迈过1万亿美元、2万亿美元,目前成为仅次于微软和苹果的美股第三大上市公司。
英伟达的另一面,在AI领域投入较慢的公司,则正在承受掉队的代价。在移动互联网时代执牛耳的苹果,一度是标普500指数中贡献最大的一家公司。受困于在生成式AI布局方面的迟缓,苹果股价年内累计下跌近10%,总市值从3万亿美元高点滑落至当前的26826亿美元。
但面对年内不到一个季度,股价便累计暴涨近八成的英伟达,资本市场也开始产生分歧,部分机构从看涨变为套现离场,如方舟投资管理公司基金经理凯茜·伍德(人称“木头姐”)。
看着英伟达股价几乎每天都在创造新纪录,近期,瑞穗证券分析师Jordan Klein在一份报告中提醒道,“感觉有点不健康,让人想起1999年和2000年疯狂的科技市场心态。”
随着投资者“恐高”情绪的蔓延,Jordan Klein等分析师试图给过热的市场降温。花旗更是在报告中指出,英伟达面临的回调风险正在加剧。
在资本市场已经显现出分化局面的情况下,尽管有B200芯片的全新加持,英伟达当天股价也经历了一波大涨到微涨的变化,股价涨幅从盘中超4%,下落至收盘后的0.7%。
盘后,英伟达股价下跌1.76%。
面对每一次技术浪潮带来的市场变革,50 Park Investments创始人兼首席执行官亚当·萨兰表示,“我们一次又一次地看到当投资者被当下的技术创新理念所吸引时,逻辑就会被抛到一边。当感性占据上风,股价就有无限上涨空间。”
英伟达,无疑正成为当下投资者理性与感性博弈的风暴中心。
A
继两年前推出Hopper架构后,英伟达带着全新一代的Blackwell再次震撼AI界,黄仁勋希望以此开启AI的变革时刻。
基于Blackwell架构开发的B200芯片,在制程工艺上延续了H100的5nm,不过为了尽最大可能提升算力,英伟达在B200上首度采用了封装工艺,B200由两个基于台积电4NP工艺的Blackwell GPU组合而成,总晶体管数量达到2080亿个,是H100(800亿)的2倍多,且能够提供高达20 petaflops的算力,是H100(4 petaflops)算力的5倍。

(左为B200,右为H100)
性能提升的同时,B200在成本和能耗上,相比H100,最高可以降低25倍。叠加B200搭配的8颗HBM3e内存,最大可支持10万亿参数模型的训练。作为对比,OpenAI的GPT-3 模型参数为1750 亿,据黄仁勋透露,GPT-4模型参数约为1.8万亿。
以训练一个1.8 万亿参数模型的GPT-4为例,之前需要用8000个Hopper GPU干的活儿,现在用2000个Blackwell GPU就能做到,且功耗还减少至原来的约1/4,即从15 兆瓦降至4兆瓦。
如果想要更强性能,用户只需把两个B200 GPU与一个Grace CPU相结合,就能搭建为GB200超级芯片,其可以为大语言模型的推理环节提升30倍的工作效率。
在具有1750 亿个参数的 GPT-3 LLM 基准测试中,GB200的性能是H100的7倍,训练速度则是H100的4倍。
值得一提的是,Blackwell并非某一款芯片的专属名,而是指代英伟达的新一代芯片平台。基于该平台,英伟达提供有多种服务器节点规格,性能从小到大依次为:HGX B100,HGX B200,以及GB200 NVL72。
HGX B100配备x86 CPU和8个B100 GPU。HGX B200使用8个B200 GPU 和1个x86 CPU。最强大的GB200 NVL72系统,则配备36颗Grace CPU和72块Blackwell GPU,具有1440Peta FLOPSde FP4 AI 推理性能,和720 Peta FLOPS的FP8 AI训练性能。
“一个GB200 NVL72机柜可以训练27万亿参数的模型。”黄仁勋介绍道。这意味着,一个GB200 NVL72机柜,便可以撑起约15个GPT-4参数规模的大模型。
不过,英伟达并未明确给出B200芯片的具体上市时间和价格,只表示将于今年晚些时候发货。届时,亚马逊、谷歌、微软和甲骨文,将成为首批提供Blackwell芯片驱动的云服务提供商。
B
除了制程工艺上的停滞,会让外界担忧英伟达继续保持AI芯片领先姿态的持久性外,高涨的AI热情可能带来的库存挑战,也让部分投资机构打起退堂鼓。
“以2017年为例,那时加密货币行业的兴起导致对英伟达GPU需求激增,一度导致市场对其需求过于旺盛,即市场参与者急于购买GPU,以至于出现了超出正常需求的多倍订购,这最终导致了库存积压。每当我听到为了应对短缺而进行双倍订购、三倍订购、四倍订购时,我都会远离。”
现实层面,一众大公司的确在争相抢购英伟达芯片:扎克伯格宣布要建立一个“大规模计算基础设施”,到2024年底将包括近60万个GPU储备,其中涵盖35万张英伟达H100显卡;亚马逊也开始筹划建设世界上最快GPU推动的AI超级计算机,计划配置超过1.6万张英伟达GH200超级芯片。B200芯片发布后,亚马逊率先表态,称AWS已计划采购由2万张GB200超级芯片组建的服务器集群。

在越来越多大公司以高于实际需求而抢购英伟达芯片之际,后者供货的速度却远远达不到预期。
在四季度财报会上,黄仁勋再次提醒道,来自供应链的短缺,正加剧芯片供应现状。
无论是上一代H100,还是全新一代的B200,都需要用到HBM内存。生成式AI爆发之前,因为成本高昂,HBM模式并未得到大规模市场化,全球预备产能并不多。目前SK海力士独占HBM近一半市场份额,即便加上新入局的三星和美光,其能否满足英伟达需求都成问题,更何况还要将原本就捉襟见肘的产能,分润给英伟达的竞品,如谷歌、AMD等自研AI芯片。
HBM环节之外,一颗英伟达AI芯片的最终诞生,还需要经过台积电的CoWoS封装。在5nm工艺节点下,目前仅有台积电可以大规模量产CoWoS先进封装。原本供应H100都不够用的CoWoS封装产能,如今还得给同样采用5nm的B200让路。
而不论是HBM还是CoWoS,想要进一步提升产能,都至少需要近一年的时间提前规划。
因供不应求而无法满足市场需求的英伟达,也给后来者留下了竞争的生存空间,AMD、谷歌、微软、亚马逊、Meta等已有的友商之外,一些新的竞争对手仍在不断赶来。
进入2024年,奥特曼开始喊出7万亿美元的芯片全产业链制造计划,软银创始人孙正义被爆出正寻求高达1000亿美元资金,计划打造抗衡英伟达的AI芯片巨头。
随着越来越多公司加入AI芯片产品研发队列,不排除会进一步加剧未来市场上的AI库存压力。
C
相比芯片库存所带来的远期泡沫,不少投资者在英伟达不断刷新纪录的股价面前,已经开始出现“恐高”情绪,越来越多的声音试图给过热的市场降温。花旗报告中指出,投资市场呈现出过度乐观和“一边倒”的趋势,股市面临的回调风险加剧。
瑞穗证券分析师Jordan Klein表示,投资者似乎陷入了“纯粹的追逐模式”,这种市场行为导致半导体股价格不断走高,形成了一种“自我强化”的趋势。“投资者应该记住,英伟达等AI芯片股‘不可能每天都上涨’,就像最近看起来不自然的行情那样。”
“木头姐”率先付诸行动。从2023年四季度开始,木头姐抛售英伟达的力度逐渐加大。对于抛售行为,木头姐对外解释:“2014年,多数投资者还把英伟达视作一家PC游戏芯片公司,我们就选择以5美元的价格买入。如今,英伟达的收益已经超过了150倍,我们选择获利了结。”

在3月份致股东的一封信中,木头姐进一步对英伟达敲响警钟,警告其惊人的增长可能会放缓。“从长远来看,与思科的历史轨迹相异,英伟达的竞争环境可能会更加严峻。这不仅仅是因为部分竞争对手正在逐步取得市场成功,更关键的是,英伟达的主要客户,包括云服务提供商和特斯拉等公司正在积极设计自主的人工智能芯片。”
自2000年互联网泡沫破裂后,思科股价在随后几年内暴跌约90%,此后一直未能回到互联网泡沫巅峰时期。在木头姐看来,今天的英伟达,就是昨天的思科。“正如当年思科交换机和路由器引发互联网革命一样,英伟达是推动人工智能革命发展的关键公司,所以它的股价也会经历较大的起伏和波动,就像思科在股市上经历的那样。”
但相比思科当年高达100倍的市盈率,以及频繁的大额投资和收并购行为,当前的英伟达市盈率仍维持在不到30倍低水平,同时借助其不断增长的营收和利润,英伟达资产负债表也要好于思科。
但正如Jordan Klein所言,没有一家公司的股价会一直上涨。投资者谁也不敢保证自己会不会买在了高点。
参考资料:
《见证AI的变革时刻》黄仁勋
《英伟达崩了,谁的锅?》华尔街见闻
《一位亿万富豪投资人开始警惕美股塌陷风险了》福布斯
《是谁卡了英伟达的脖子?》远川科技评论