这个问题在知乎上昨天半夜出现,到现在十多个小时,每次点击进来,排名第一的答案的赞数总是在发生巨大的变化。有时候是六千多,有时候只剩两千,有时候是一万多,有时候只有几百。但不管城头大王旗如何变幻,唯一不变的是:下次你再点进来的时候,之前排名第一的那个答案已经常常就不见了,被反对到不知道什么地方去了。
等你向后翻页、翻页、翻页,不断翻页,总算在刚刚出现的0赞答案后面翻到这些万赞答案,才会意识到,这些万赞答案到底拿了多少反对票,才能排到这儿呀。
所以,在这个问题里面,我先不评价这场比赛,不评价去看比赛的观众,也不评价其他答案,而是单单评价刚刚说到的这个现象——由于首位赞同被大量反对,造成首位答案不断变化,这会使得出现在问题首位的答案赞数往往比较低。
那么,这类问题的首位答案赞同数除以这个问题的总阅读数,其实就可以体现出这个答案的「意见统一度」。当这个比例比较高的时候,说明问题阅读者赞同回答前几名的概率很高,读者意见统一比较高。反之在意见统低度较高时,则说明问题阅读者反对或赞同前几名的答案的概率差不多,会使首位答案不断变化,赞数始终无法积累。
我将这个指标称之为——首位赞读比。
那么,以目前2019年10月11日下午2点为准,这个问题的前五名回答分别有3033、8764、221、2098、372票,平均每个回答2897.6票,整个问题共有10794746个阅读,那么他的首位赞读比就等于万分之2.68。
然后,我收集了去年一整年来我回答或关注、且阅读量在500万以上的一共20个问题,把他们的前五名答案的赞同平均值除以答案的阅读量,做了一个排序,如下图所示:

第一名是有关上海迪士尼翻包,第二名是教育部是否应该减负,第三名是顺风车司机杀人的责任归属,这三个问题的首位赞读比都在千分之一以上,说明这几个问题大家的「意见统一度」比较高。
这两个问题,首位赞读比都只有万分之二到万分之三,大概只有前几名的20%。
那么,我们能否从首位赞读比的大小,判断出每个读者对答案的赞同/反对概率呢?
答案是肯定的。首先让我们回顾知乎的排序算法
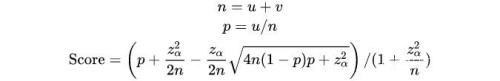
接下来,我们取等于5%双侧置信区间的阈值1.96,做了一个模拟。我们假设一个问题有100个回答,每个答案初始赞同数和反对数都是0-5之间的一个随机数,模拟顺序如下:
1,每次阅读会让读者看到排序前5个回答。
2,读者会对这5个回答给出赞同/反对的评价,赞同/反对取决于这个问题的「意见统一度」,当「意见统一度」接近1时,读者几乎肯定会给出赞同的评价,反之则会给出反对评价。
3,根据威尔逊算法重新排序后,再次呈现排序前5名的回答,重复5000次。
4,将「意见统一度」从0到0.99遍历100次。
这样重复了五十万次试验后,用前5个答案的平均赞同除以5000,计算「首位赞读比」,和「意见统一度」做散点图如下:
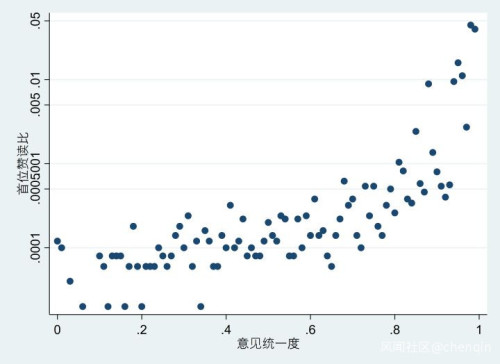
可以看到,千分之一到千分之二的「首位赞读比」对应的是0.9左右的意见统一度,也就是10个读者里面有9个会赞同这个答案。
而万分之二到万分之三的「首位赞读比」,对应的是0.6左右的意见统一度,10个读者来看,只有6个会给赞同,另外4个会选择点反对。
10个人里面,6个赞同4个反对。
我写到这里,这个问题的答案已经超过了7000个,其中写答案表达了反对意见的可能不超过5%,大概2%都没有,看起来是一个一面倒的意见。但当前几名的答案呈现给一个随机的读者时,他却有4成的可能默默点下了一个反对。
他们没有发声写出自己的看法,也没有构成「沉默的大多数」,但却构成了「沉默的近半数」。
调查涵盖了2379名被访者,其中包括了被访者的学历、收入、职业,以及对许多问题的看法,其中有一个问题是这样的:

把“不知道”去掉后,结果如下:
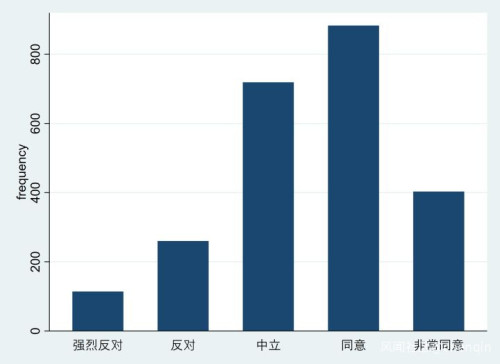
15.7%的被访者选择了「反对」或「强烈反对」,55.1%的被访者选择了「同意」或「非常同意」。
分教育程度看则是这样的(每行加总为100,每个格子代表每个学历被访者选项分布):

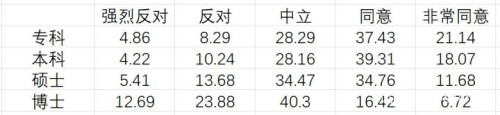
如果只看专科、本科、硕士、博士,趋势更加明显:
再来看分家庭年收入情况的分布:
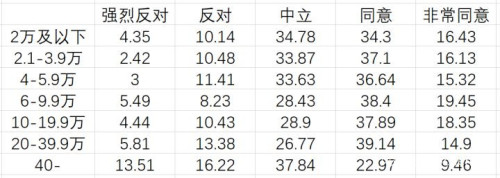
最后再看分职业情况的分布,最右一列是填写该职业的被访者人数:
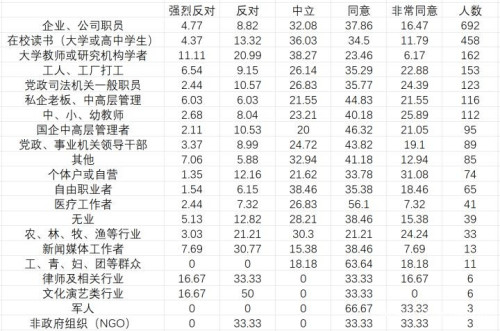
从这几张表中,我们可以看到,选择了把个人利益放在了国家利益之上的,主要都是哪一些特征的人群。
可是,他们为什么没有发出自己的声音,唯独沉默呢?我找到了一个可能的理由,也是在网民社会意识调查中的一题:


这个问题的回答,和国家利益与个人利益一题的回答,有什么样的关系?
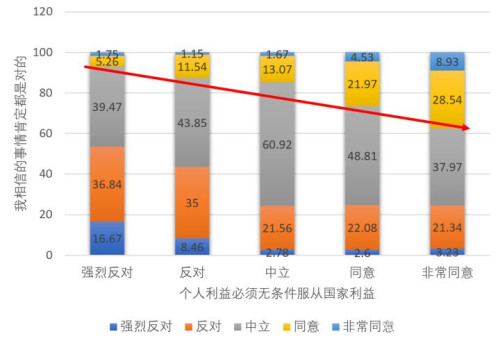
上图的横轴为「个人利益必须无条件服从国家利益」的答案,纵向的分布为「我相信的事情肯定都是对的」的答案。看到「我相信的事情肯定都是对的」从左到右的的「同意」比例从7.01%上升到37.47%,我感觉似乎找到了问题的答案。


