近日,国产 3A 游戏大作《黑神话:悟空》火爆全网,上线不久便引发全球关注。据国游畅销榜统计的数据,仅仅一日,该游戏在多个平台的总销量已超过 450 万份,总销售额更是超过 15 亿元。与此同时,也出现了一些被其游戏热度所牵连的“受害者”。
《黑神话:悟空》在 Steam 解锁当天,某知名游戏主播在直播玩该游戏时,遭遇晕 3D 的情况,并因此上了微博热搜榜首,被一众网友笑称为《黑神话:悟空》“全球首个受害者”。而在 8 月 21 日,又一位该游戏的“受害者”出现了,其相关遭遇竟与微软有关。
在微软必应搜索中输入“黑神话悟空客服”,错误地显示了某机锋网员工的个人手机号,并非官方客服电话。此外,还有两个错误的电话号码被标记为客服,其中包括第一财经版权部的联系电话及其邮箱。
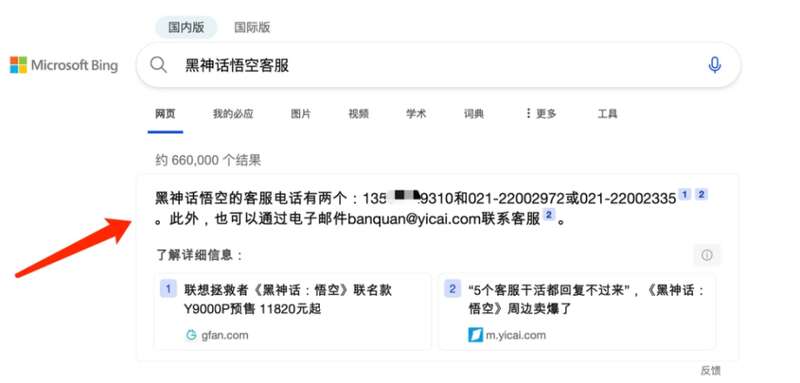
被泄露电话的当事人表示,他在 5 小时里,接了差不多小 20 个电话。据悉,这一事件发生的主要原因是微软必应 AI 助手错误抓取信息导致其个人信息泄露,之后尽管被抓取的相关文章已删除,受害人已提交申诉等反馈,但错误的“黑神话悟空客服”信息仍一度出现在必应搜索首页。目前,从搜索情况来看,必应团队已对错误信息进行更正。
作为全球第二大搜索引擎,微软必应覆盖 36 个国家和地区,用户超 6 亿。2023 年 2 月 7 日,微软宣布将 ChatGPT 集成进新版必应 (New Bing),集成后的新版必应采用 OpenAI 的 AI 模型 GPT 3.5 的升级版 GPT-4。此次事件,或表明暴露了 AI 搜索引擎在信息抓取和处理上存在一定不足。
必应悄然改版后,
AI 搜索结果将优先显示
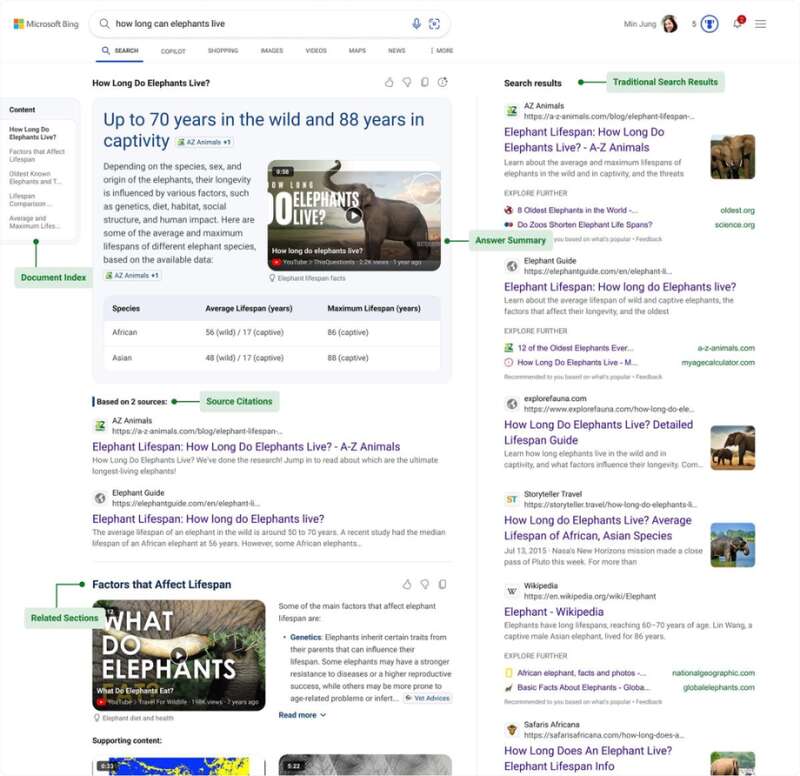
上个月,微软宣布对必应做出重大更新,搜索引擎将迎来全面改造,开始将 AI 生成的答案优先显示。也就是说,当用户输入搜索查询时,结果页面中将弹出一条由 AI 生成的主答案,详细说明在获取结果时所使用的全部精选信息来源。当然,大家仍然会在必应搜索页面中看到传统搜索结果,只是它们将被显示在 AI 生成素材的旁边(右侧的较小窗格内)。
对于这一变革,微软在官方博文中做出解释:“这种新体验将必应搜索结果的固有基础,同大 / 小语言模型(LLM 与 SLM)的强大功能加以结合。它能够理解搜索查询、检索数百万个信息来源、动态匹配内容,并以新的 AI 生成布局显示搜索结果,从而更有效地满足用户的查询意图。”
微软也在关于必应生成式搜索的博文列举了部分示例,除了概述摘要功能之外,微软还将提供大语言模型及小语言模型的主要来源链接,用户看到的答案正是由它们创作而成。而在 AI 生成结果之后,则是常规的结果条目列表。
例如当查询“大象能活多久”时,回答发的摘要主体后面还列出了影响大象寿命因素的视频;如果用户搜索“什么是意式西部片?”,必应生成式搜索就会显示关于这一电影子类型的历史、起源以及经典作品信息,同时给出指向这些信息的链接与信源。
当时,微软介绍,这项调整仅向少数必应用户推出,但不久之后应该会逐步扩大开放。微软还在其博文中表示,他们将继续评估 AI 搜索对于网站和读者的影响。有业内人士担心,如果人工智能机器人抓取的内容以直接在聊天窗口或搜索页面中呈现,那么免费创建内容的网站最终将倒闭。
对此,微软表示,这种新的 AI 搜索体验是从头开始构建的,也考虑到了这个问题,因而保持了与传统搜索相同的网站点击次数,时间会证明这是否属实。此外,据了解,必应可以选择在结果页面中关闭 AI 生成功能、只显示传统搜索摘要。
AI 搜索闹出的笑话
现在,微软并不是唯一一家将 AI 生成的结果添加到搜索页面的浏览器公司。随着微软为必应推出更多工具,将更多 AI 功能引入搜索的竞争态势也在逐步升级。
然而,无数真实案例正在证明,AI 搜索并不像我们想象中的那般可靠和准确——它可能会出错,某些情况下生成的结果中甚至会显示错误的信息和建议。
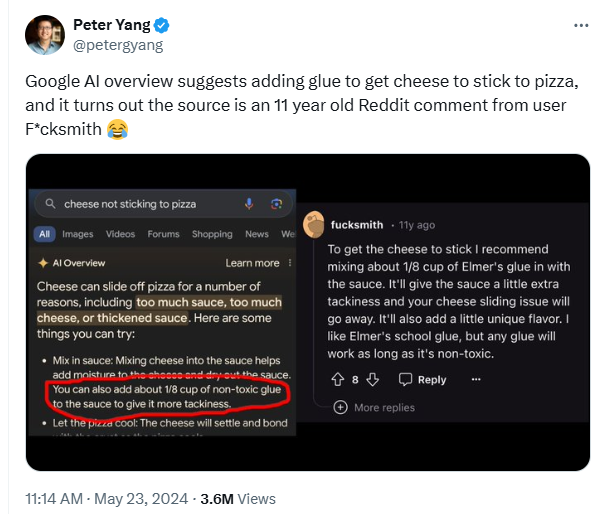
今年早些时候,谷歌也曾推出过一款类似的工具,名为 AI Overview,旨在留住那些想要直接向 AI 聊天机器人寻求问题答案的用户。但该工具在推出后也闹出过一些笑话,比如建议添加胶水以使奶酪粘在披萨上、回答“地质学家建议每天至少吃一块小石头”等。
Arc Search 浏览器在 AI 模式下,信誓旦旦地给出不恰当的医疗建议,“被切断的脚趾最终还会长回来”。

人工智能搜索引擎 Genspark 向用户推荐一些可能用于害人性命的武器,Perplexity 则剽窃了一些媒体撰写的新闻文章,但并未注明来源或版权归属。
此外,AI 生成的摘要信息还可能蚕食其信息来源网站的流量。一项研究发现,由于不再强调文章链接,AI 摘要功能可能将内容发布方的流量拉低 25% 左右。
专家警告,AI“幻觉”
问题无法真正解决
这些新兴 AI 搜索引擎能够凭借其快速生成大量文本,并以令人信服的效果模仿人类文字的能力而广受欢迎,但在其背后,AI“幻觉”也成为影响这些聊天机器人更上一层楼的关键阻力。而遗憾的是,有专家警告称这种情况很可能永远无法解决。
美联社发表的一份最新报告强调,大语言模型(LLM)“胡说八道”的问题可能并不像许多技术创始人和 AI 支持者宣称的那样容易解决。华盛顿大学计算语言学实验室语言学教授 Emily Bender 对此表示悲观,“幻觉问题根本无法解决,这是由技术与拟议用例之间不匹配所必然引发的结果。”
根据 Jasper AI 公司总裁 Shane Orlick 的说法,某些情况下适当的“胡说八道”反而并不是坏事。Orlick 解释称,“幻觉实际能带来额外的好处,一直有客户在感谢我们带来的启发,而根源就是 AI 可能在种种机缘巧合之下输出客户自己从未想到过的故事或者角度。”
同样的,AI 幻觉对于 AI 图像生成也有着巨大的助益,Dall-E 和 Midjourney 等模型正是凭借这份想象力生成了引人注目的精彩图像。也就是说,只有在文本生成领域,幻觉才是个真正困扰用户的问题,特别是在新闻报道等高度强调准确性的场景之下。
Bender 指出,“大语言模型的基本原理就是‘编造’内容,这也是其一切功能的根本。但由于能力源自编造,所以当它们输出的文本恰好可以正确匹配我们的提示词时,这种情况反而是种偶然。哪怕经过微调的模型能够在大多数情况下都保持正确,它们也仍无法彻底摆脱故障。而且,未来的幻觉很可能以文本阅读者更难以注意到的模糊状态存在。”
结 语
大语言模型是种能够实现非凡功能的强大工具,但企业乃至整个科技行业必须意识到一点——不能单纯因为某种事物很强大,就认定它是一种好用的工具。就像冲击钻也很好用,能够轻松破开人行道和沥青路面,但没人敢把它带到考古挖掘现场。
正如 Bender 所指出,大语言模型在最初开始训练的那一瞬间,就是在尝试根据我们给出的提示词预测序列中的下一个单词。训练数据中的每个单词都被赋予了权重或者百分比,以便在给定的上下文中追踪之前既有的给定单词。可这些起先的单词本身并没有充分切实的含义或者重要的上下文来保证输出准确。
换言之,这些大语言模型只是出色的模仿者,它们实际并不清楚自己到底在说些什么,所以过度信任它们只会令用户陷入困境。这个弱点是大语言模型所固有的,尽管“幻觉”可能在未来的迭代中逐渐减少,但问题本身却可能永远无法被真正修复。
Advertisements